本文内容来源于网络博客及GPT生成内容,作者并未详细阅读论文原文
九月份创建的笔记,十二月份才开始动笔。真正写内容时才发现这些网络其实没有到需要记笔记的地步,但既然写都写了,还是送佛送佛到西,简单介绍一下它们的内容吧
WetMapFormer
1. 论文信息
| 属性 | 详细信息 |
|---|---|
| 标题 | 🔬 WetMapFormer: A unified deep CNN and vision transformer for complex wetland mapping 🔬 WetMapFormer:用于复杂湿地制图的统一深度卷积神经网络与视觉Transformer |
| 会议 | 📚 International Journal Of Applied Earth Observation And Geoinformation 🌍 地球科学1区 [TOP] |
| 日期 | ⏲️ 2023-5-11 |
| 作者 | 👨🔬 Ali Jamali |
作为较早将 Transformer 架构用于湿地地物覆盖分类的工作,WetMapFormer 对当前的我参考价值已比较有限。因此,这里我只简要记录其模型结构和部分实验细节。相关实验信息如下:
| 项目类别 | 内容 |
|---|---|
| 实验区域与样本 | Grand Bay-Westfield;York County;Albert County 及三地实地采样样本 |
| 湿地地物类别 | Aquatic bed 河床?、Bog 沼泽、Fen 草本沼泽、Forested wetland 森林湿地、 Fresherwater marsh 淡水沼泽、Shrub wetland 灌木湿地、Water 水体 |
| 遥感影像 | S2 L2A (10): 使用2021/06/01与2021/09/01的两期影像制作 中值合成影像(median composite);S1 GRD (4): 使用 GRD 数据的四种极化数据; 上述数据使用GEE下载,没有做额外处理 |
| 训练样本划分 | Train : Valid : Test = 6 : 1 : 3,采用分层随机抽样划分数据保证三个数据集中均有所有类别标签 |
2. 网络结构
WetMapFormer 的整体框架如下图所示:
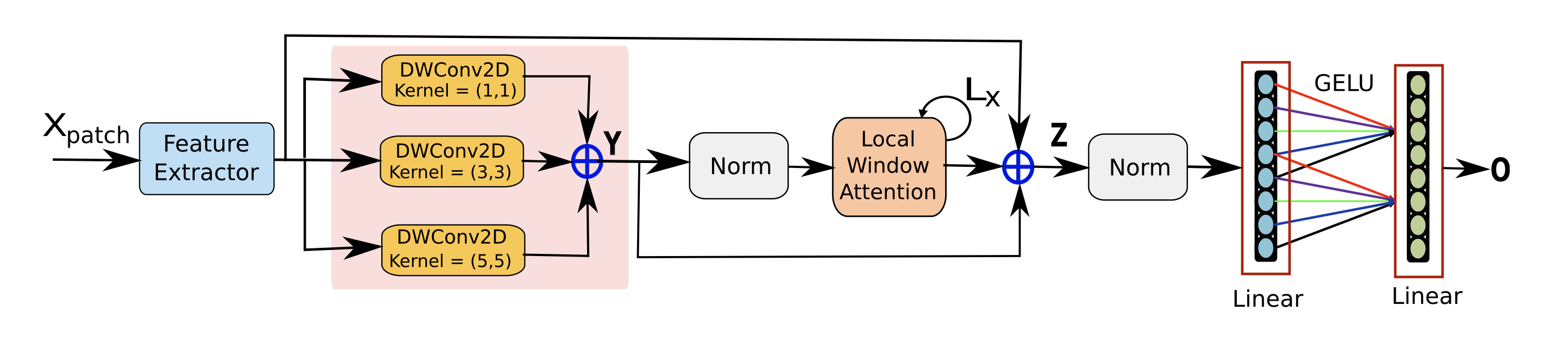
从图中可以看出,网络主要由三个核心组件构成:Feature Extractor、DWConv2D Group 与 Local Window Attention。下面我们来快速过一下它们的结构。
🌟 FE模块
WMF 首先使用一个轻量级CNN模块对输入patch进行空间特征提取,结构如下图所示:
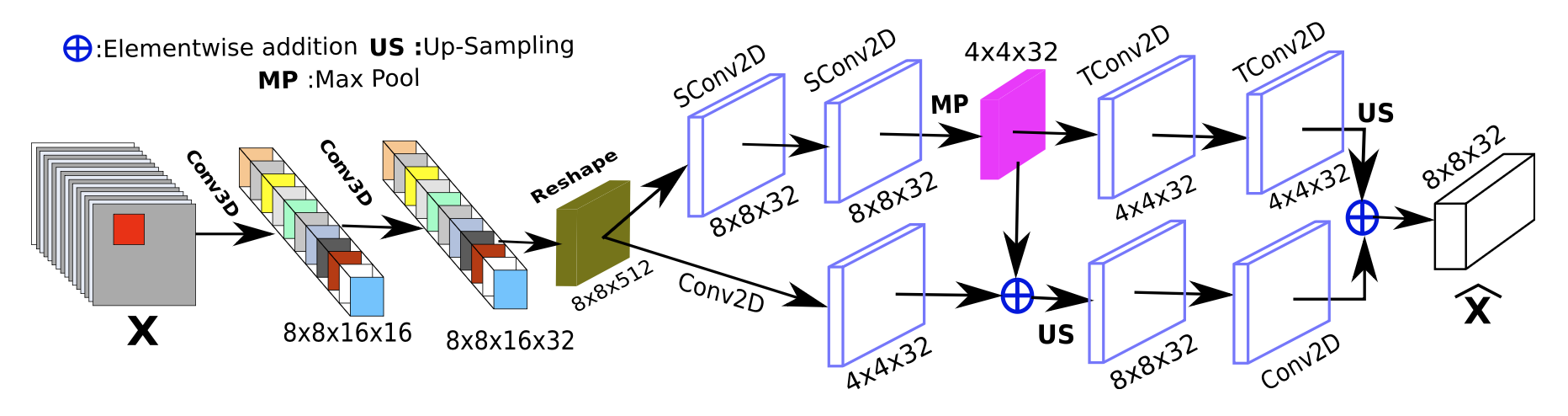
该模块接收尺寸为16@8x8的输入特征。其中16个通道来自 S1 与 S2 影像的拼接,并可能包含若干遥感指数特征。显然该网络并未专门设计显式的多源融合模块,而是直接将多源信息堆叠后交由 FE 及其后续模块自动学习融合关系。
FE 模块先将输入reshape为8x8x16x1的张量,并通过两层3D卷积进行处理(卷积核通道数分别为16和32)。3D 卷积的主要作用是扩展并变换第4维度(初始大小为1),从而提升通道间交互能力。随后模块将特征reshape回 2D 格式,最终输出一个512@8×8的高维特征图。
值得注意的是,FE 模块的内部结构在图示中略显抽象,但结合其源码可以发现,它实际上实现了一个双层 U-Net 风格的编码器-解码器结构,并在末尾使用Upsample统一多尺度特征,从而增强对局部空间信息的表征能力。
🎨 深度可分离卷积
在完成初步的空间特征提取后,WMF 使用并行 深度可分离卷积 | Depthwise Separable Convolution 进一步增强特征表达能力。
这里简单回顾其运算机制:
假设输入特征图尺寸为 。在标准卷积中,我们使用 个大小为 的卷积核进行处理,其参数量与计算成本较高。为显著降低计算与参数开销,深度可分离卷积将这一过程分解为两个顺序执行的步骤:
- 逐通道卷积 (
Depthwise Conv):使用 个 的卷积核,分别对每个输入通道独立进行空间卷积,输出 个特征图。这一步仅提取空间特征,不进行通道融合。 - 逐点卷积 (
Pointwise Conv):使用 个 的卷积核 (1x1 Conv2D),对上一步输出的特征图进行线性组合,以控制输出通道数并实现通道间的信息交互,最终输出一个与普通卷积尺寸相同的特征图。
将两者结合可在保持表达能力的同时显著降低参数量和 FLOPs,因而成为轻量化视觉模型中的常用组件。
🐍 LWA模块
在 DWConv 提取细粒度空间特征后,WMF 引入了一种基于 ViT 的局部注意力模块 Local Window Attention (LWA) ,进一步增强模型的空间建模能力。
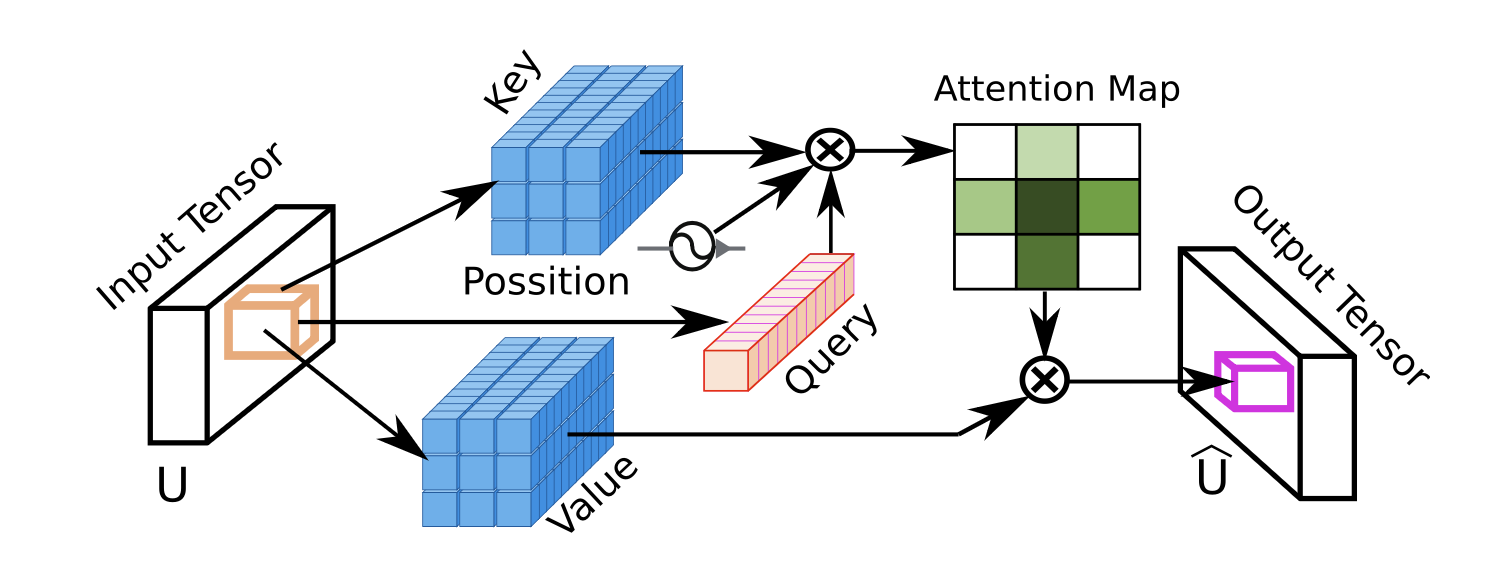
LWA 模块可以看作卷积操作与多头自注意力机制(MHA)的混合体,它在每个像素位置构建一个kernel × kernel的局部窗口,将该窗口内的邻域像素序列作为 Key/Value,并以当前像素的特征向量作为 Query,通过 MHA 计算得到自适应的空间聚合特征。
换句话说,LWA 不再固定使用卷积核参数对邻域内容进行加权,而是通过注意力机制学习每个邻域像素对中心像素的影响程度,从而获得更灵活的空间上下文表达。
虽然示意图将 LWA 描述为「逐像素独立计算注意力」,但实际实现中作者进行了更高效的 向量化处理:网络会一次性为整个输入张量生成 Q/K/V,然后再使用滑动窗口方式将邻域像素组织成序列。生成后的张量尺寸如下表所示:
| 名称 | 尺寸 | 说明 |
|---|---|---|
Q |
(B,HW,heads,1,key_dim) |
每个像素生成一个 Query,key_dim为每个注意力头处理的 token 维度 |
K |
(B,HW,heads,key_dim,KK) |
由每个像素对应的kernel×kernel邻域构成 Key 序列 |
V |
(B,HW,heads,KK,key_dim) |
这里的注意力机制可以理解为,在考虑像素与周围像素的相关性后提取的空间聚合特征。 |
从本质上看,LWA 使用「卷积式滑动窗口」构建局部 token 序列,再通过 Transformer 的注意力机制学习邻域相关性。因此,LWA 兼具卷积对局部结构的高效建模能力,以及注意力机制的灵活自适应特性,有效弥补传统卷积在空间关系建模上的不足。
Wet-ConViT
1. 论文信息
| 属性 | 详细信息 |
|---|---|
| 标题 | 🔬 Wet-ConViT: A Hybrid Convolutional–Transformer Model for Efficient Wetland Classification Using Satellite Data 🔬 Wet-ConViT:基于卫星数据的高效湿地分类混合卷积Transformer模型 |
| 会议 | 📚 Remote Sensing 🌍 地球科学2区 |
| 日期 | ⏲️ 2024-7-22 |
| 作者 | 👨🔬 Ali Radman |
在重新回顾这篇论文后,我越发感觉它没有阅读的必要。同上一篇 WMF 阅读笔记一样,在这里仅简单记录下一些能代表这篇论文的主要内容。
与 WMF 类似,该方法同样采用将多景光学与 SAR 影像融合为单一影像来降低影像噪声干扰,论文提出的 Wet-ConViT 网络处理的任务类型仍为的「图像分类」。论文关于样本数据集的生成步骤有一定借鉴意义,若想详细了解可以查看论文「2. Study Area and Dataset」章节,在这里就不过多介绍了。论文中具体湿地类别及样本数如下表所示:
| 类别 | 多边形数 | 样本数 |
|---|---|---|
| Bog | 98 | 42148 |
| Fen | 113 | 29648 |
| Swamp | 116 | 15424 |
| Marsh | 49 | 3445 |
| Water | 68 | 24615 |
| Forests | 103 | 35452 |
| Shrublands | 37 | 6400 |
| Grassland | 126 | 17624 |
| Pastures | 47 | 19745 |
| Barren | 24 | 1789 |
| Urban | 48 | 25308 |
| Total | 829 | 221598 |
从上表可以看出,数据集存在明显的类别不平衡问题。通常情况下,严重的不平衡会导致模型在少数类别上的表现较差,因此在训练时往往需要采取平衡处理策略,例如:使用加权损失函数、Focal Loss 或对少数类别进行数据增强。
然而,原文中提及 Wet-ConViT 模型结构能够处理类别不平衡问题,这种说法有待商榷。
The proposed Wet-ConViT model and other compared models are inherently robust to class imbalances due to their complex architectures, which are capable of learning from limited samples. The use of convolutional and transformer blocks helps capture both local and global patterns, improving the model’s ability to generalize across classes with fewer samples. Despite the imbalance, the results indicate that the proposed model achieved high accuracy in classifying various wetland classes, demonstrating its effectiveness even in the presence of class imbalance.
提出的 Wet-ConViT 模型及其他对比模型,由于其复杂的网络结构能够从有限样本中学习,本身对类别不平衡问题具备较强鲁棒性。卷积模块与 Transformer 模块的结合使用,有助于同时捕捉局部特征与全局特征,从而提升模型在样本较少类别上的泛化能力。尽管存在类别不平衡现象,实验结果表明,所提出的模型在对多种湿地类别进行分类时仍达到了较高精度,这证明了即便在类别不平衡条件下该模型依然具有显著有效性。
2. 主要内容
🌝 网络结构
Wet-ConViT 的整体框架如下图所示:
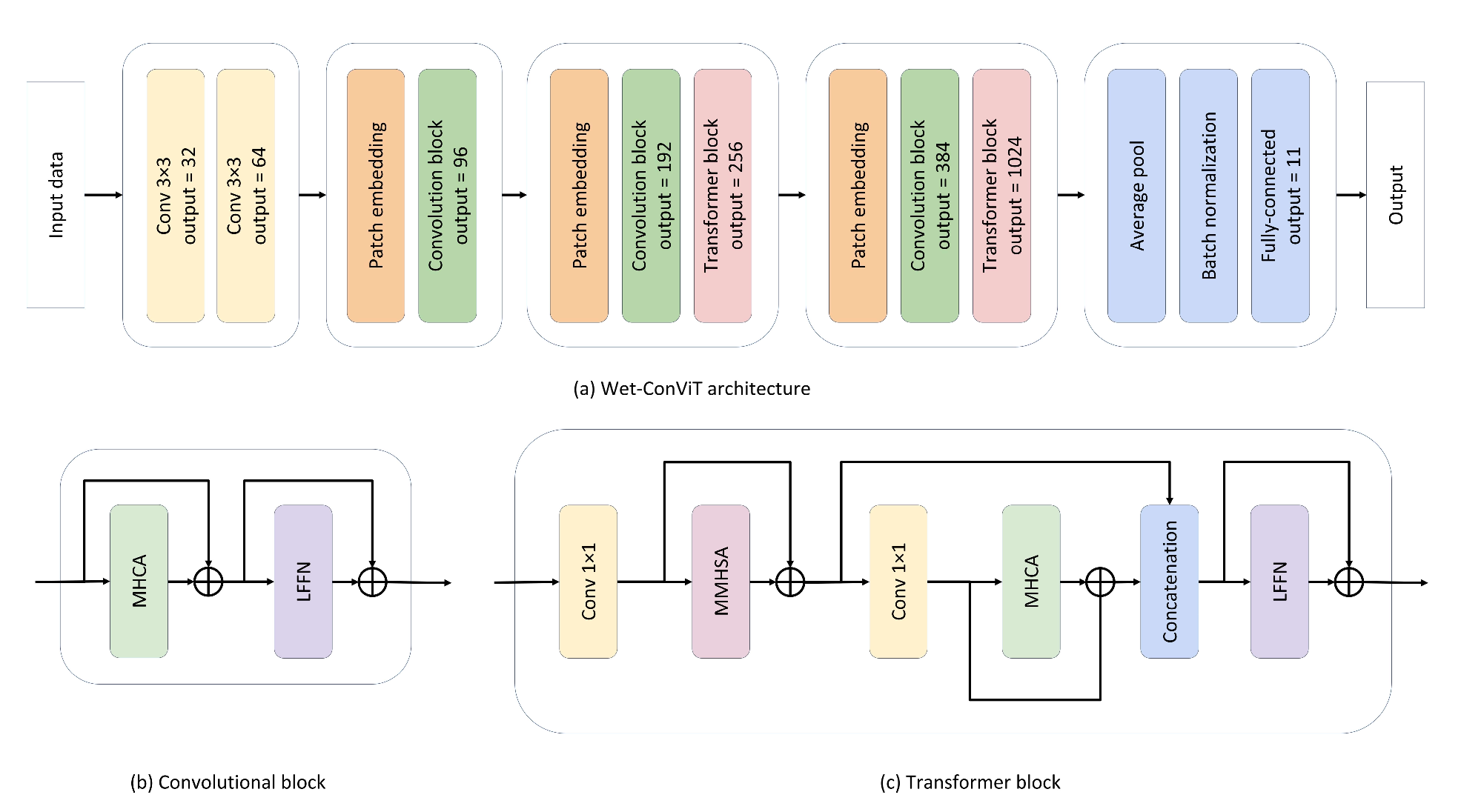
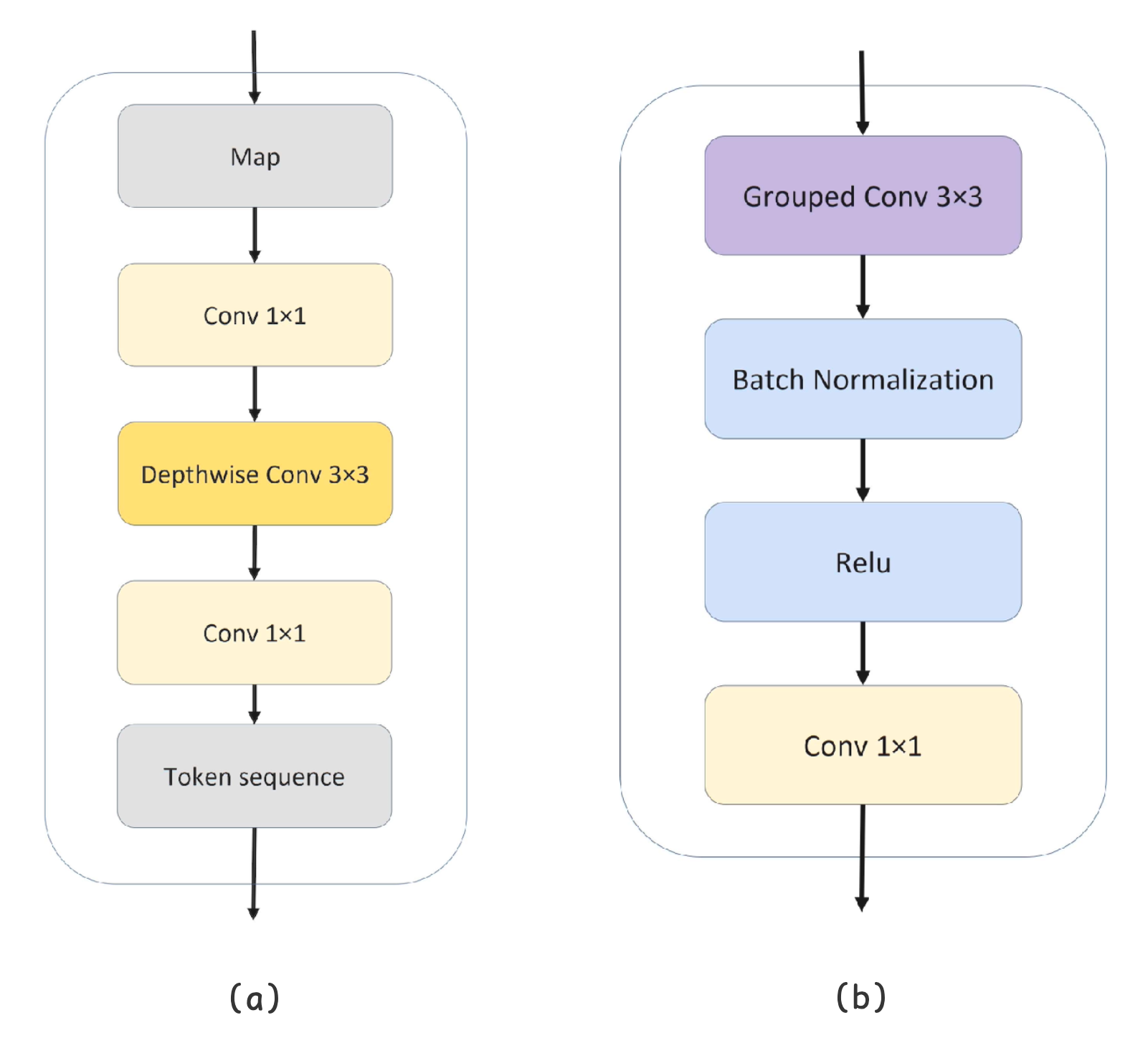
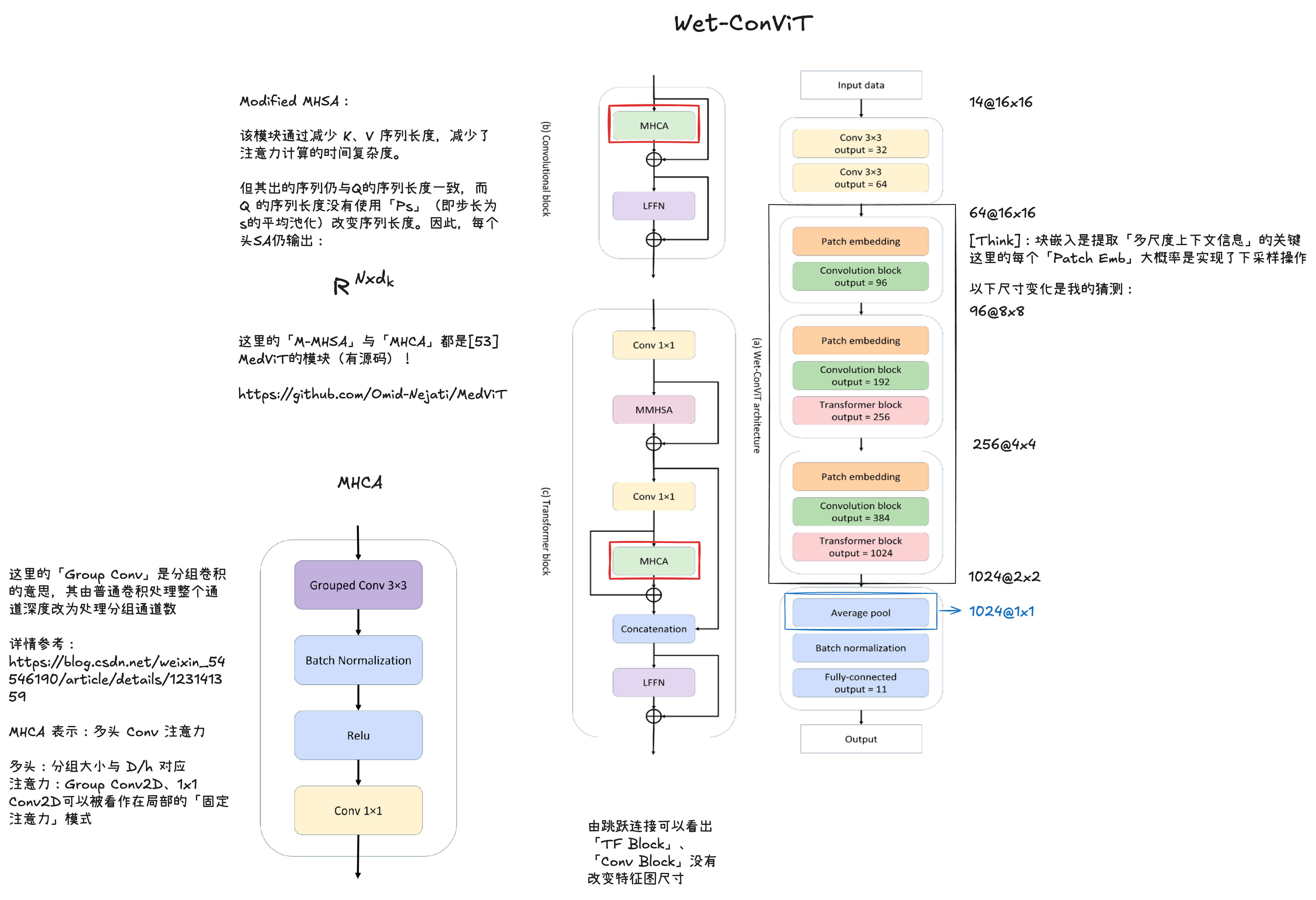
LFFN)模块(b)多头卷积注意力机制(MHCA)模块Wet-ConViT 是流水线式的结构,各特征提取模块间没有跨层级的交互、融合。对于其网络结构的总结可以参考如下GPT生成的内容总结:
| 阶段 | 模块类型 | 输出通道 | 功能 |
|---|---|---|---|
| 输入 | - | - | 原始图像输入 |
| 初始卷积层 | C | 32 → 64 | 提取低级局部特征(边缘、纹理) |
| Stage 1 | C | 64 → 96 | Patch embedding + 卷积模块:局部特征提取、升维 |
| Stage 2 | C + T | 96 → 192 → 256 | Patch embedding + 卷积模块 + Transformer block:局部特征 + 局部卷积注意力 + 全局自注意力 |
| Stage 3 | C + T | 256 → 384 → 1024 | Patch embedding + 卷积模块 + Transformer block:同上,但通道升高,捕获更高层语义信息 |
| 分类头 | - | 1024 → 11 | 全局平均池化 + BatchNorm + 全连接层,输出类别概率 |
这里使用的MHCA模块实际上来自于另一篇论文:
| 属性 | 详细信息 |
|---|---|
| 标题 | 🔬 MedViT: a robust vision transformer for generalized medical image classification 🔬 MedViT:用于通用医学图像分类的鲁棒视觉变换器 |
| 信息 | 👨🔬 ON Manzari | ⏲️ 2023 |
从示意图和代码实现来看,所谓的MHCA模块本质上仍是一个卷积模块。其内部并未设立独立的分支来提取或计算注意力,我也未能辨识出其中明显的 Q/K/V 结构(注意力不一定需要)。虽然 GPT 推测其Grouped 3x3 Conv2D可能隐式模拟了注意力机制,但我对此持保留态度。结合该论文发表的时间背景,这一模块命名的确引人联想——是否只是将卷积固有的「归纳偏置」换了一个时髦的说法?
更多可能的解释在此暂不展开。若有需要,还需查阅 MedViT 原文以作进一步判断。
🦊 可视化方法
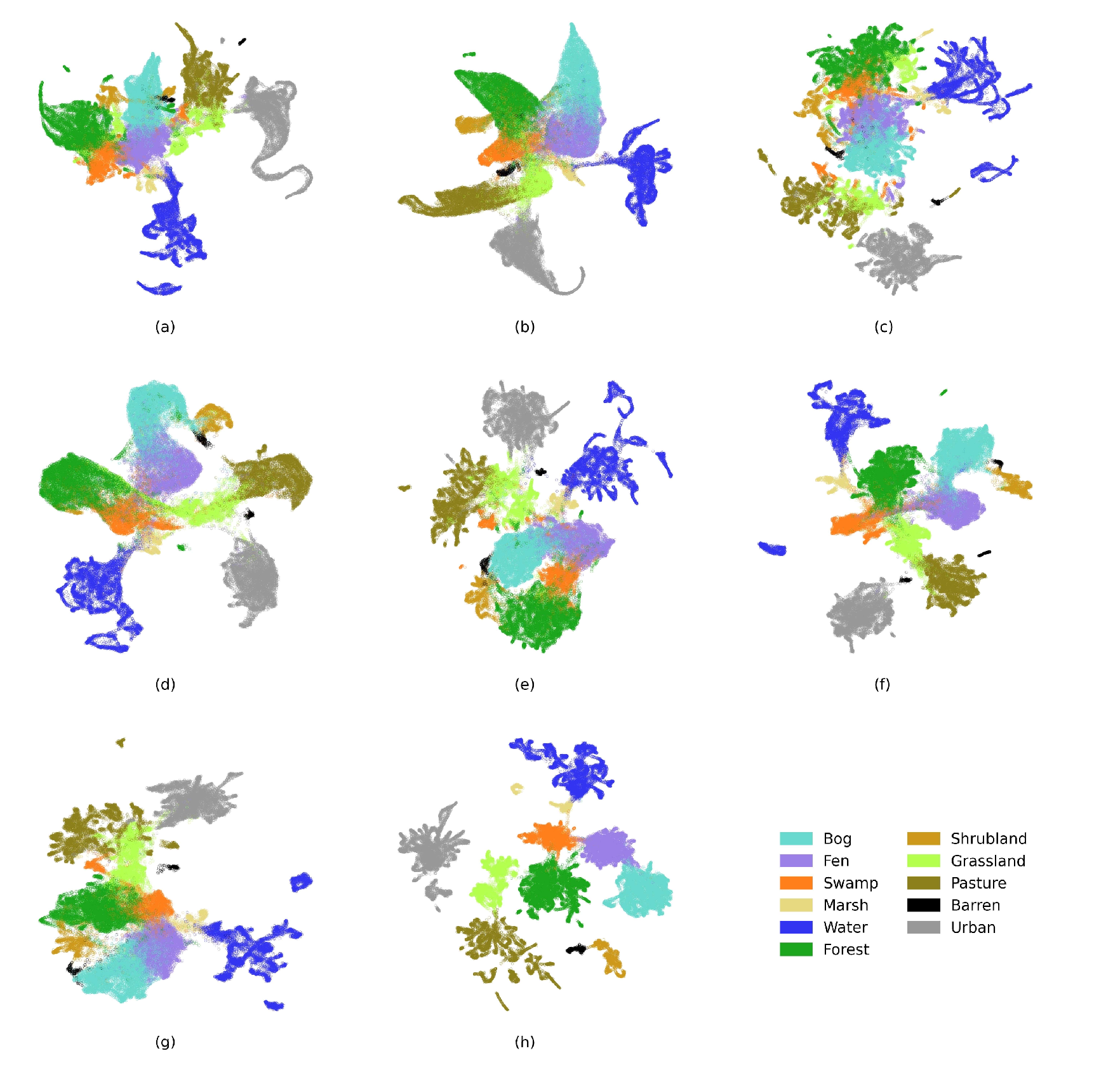
本文中采用了 UMAP 对各种 baseline 方法与 Wet-ConViT 提取的特征进行了可视化操作。
趁此机会,我也分享一下自己对深度学习论文中「特征可视化」的一些思考。目前,我了解到的深度学习特征可视化方法大致有如下几类:
- 特征空间可视化:用于观察特征向量在高维特征空间中的分布情况(例如本文关注的内容);
- 注意力可视化:用于解释模型在输入上的关注区域,例如 CAM、Grad-CAM 等方法。
- 激活/样本级可视化GPT:用于分析模型对单个样本或神经元的响应,例如 Saliency Map、Integrated Gradients、SmoothGrad 或 Activation Maximization,这些方法可以帮助理解模型对输入的敏感性以及神经元的功能。
在这里,我主要讨论第一类——特征空间可视化。其核心目标是将神经网络提取的高维特征向量映射到低维空间(通常为 2D 或 3D),以便直观地观察不同类别或不同模型的特征分布情况。这类可视化不仅有助于理解模型提取特征的能力,也能辅助分析模型的区分能力和泛化性能。
| 方法 | 说明 |
|---|---|
PCA |
线性降维方法,保留特征的全局结构,计算简单快速 |
t-SNE |
非线性降维方法,强调局部邻域关系,能够清晰呈现数据聚类,但全局结构可能失真 |
UMAP |
非线性方法,兼顾局部和一定的全局结构,计算效率较高,适合大规模数据 |
通过这些方法,我们可以将高维特征映射到二维平面,从而直观地比较不同模型在特征提取上的表现。例如,在上图中,Wet-ConViT 提取的特征在二维降维空间中呈现出不同类别明显分离的趋势,相比先前方法和通用方法,其特征的可区分性更强。
需要注意的是,虽然特征分布的可视化可以直观地反映模型的特征区分能力,但它并不能直接证明模型在任务上的最终性能,仍需结合定量评估指标(如准确率、F1-Score 等)进行综合判断。
📝 其他
最后再附上我之前的笔记吧!
CVTNet
1. 论文信息
| 属性 | 详细信息 |
|---|---|
| 标题 | 🔬 CVTNet: A fusion of convolutional neural networks and vision transformer for wetland mapping using sentinel-1 and sentinel-2 satellite data 🔬 CVTNet:基于Sentinel-1和Sentinel-2卫星数据的湿地制图——卷积神经网络与视觉Transformer的融合模型 |
| 会议 | 📚 Remote Sensing 🌍 地球科学2区 |
| 日期 | ⏲️ 2024-7-2 |
| 作者 | 👨🔬 Mohammad Marjani |
总算熬过补完前两篇论文笔记的阶段😩,回头再看这篇更是位重量级模块组装选手。不过这篇论文确实还是有些可以记录的内容,下面就由我来一一介绍吧。
与前两篇论文在实验数据介绍上的模棱两可,本文对数据来源与处理流程的描述要清晰得多。论文不仅说明了影像数据的获取方式,还列出了标签数据的分布情况,尤其具体阐述了如何从矢量多边形数据(Polygons Set)生成用于训练的图像块(Patch)及其对应类别标签。
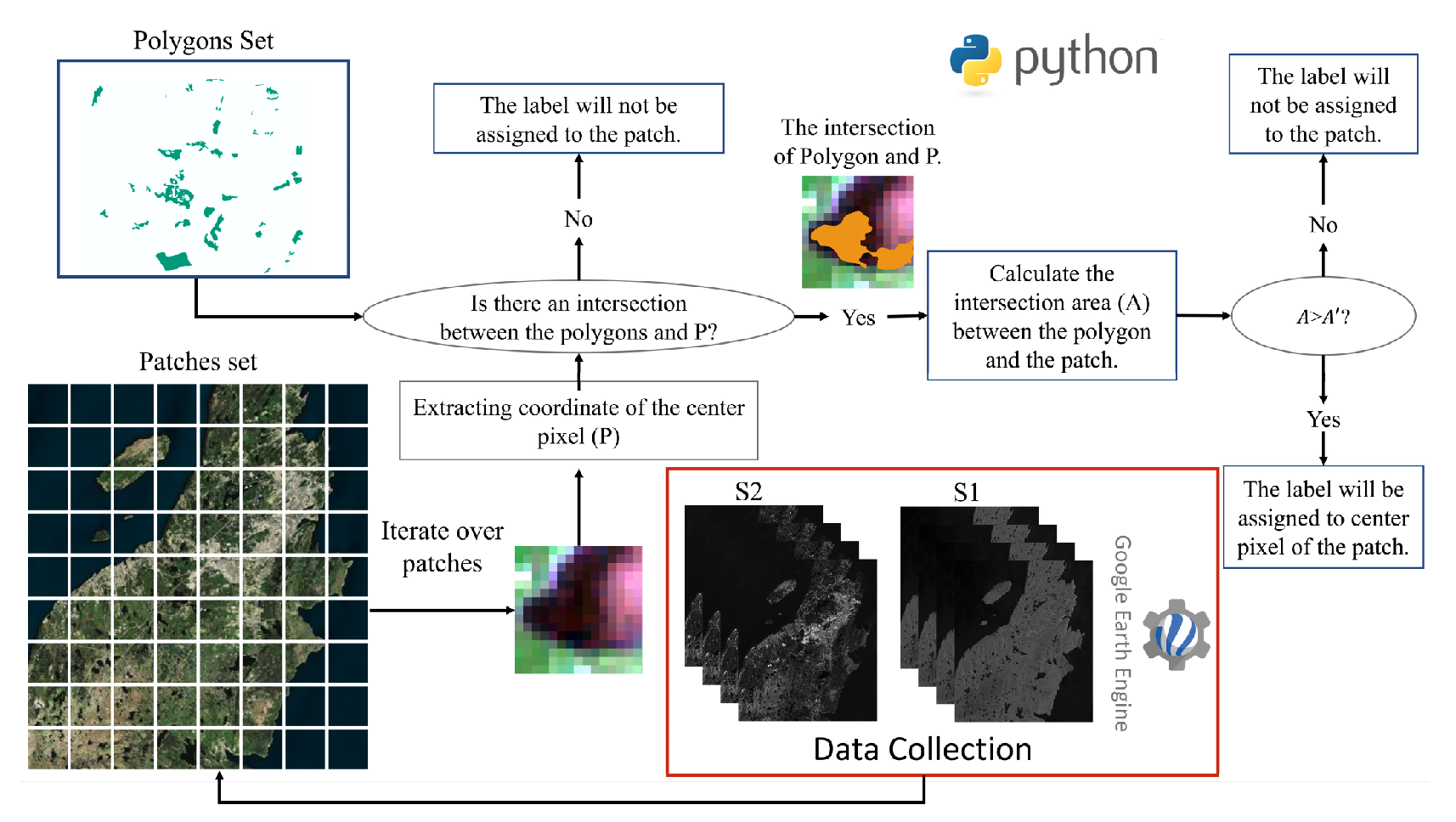
需要注意的是,这里的标签生成方法并非简单地在标注像素周围截取图像块,而是综合考虑了图像块之间的重叠率,并依据每个图像块的中心点位置及其所覆盖的各类别多边形面积的比例,来动态确定其类别标签。
这里的重叠率是指待分配标签的 Patch Set 是按一定规则预先划分的,文中使用重叠率为 。而选择与 Patch 中心点重合的多边形列别作为候选类别,保证了标签分配的唯一性。
这里使用的标签分配方法实际上也是参考了一篇论文:
属性 详细信息 标题 🔬 WetNet: A spatial–temporal ensemble deep learning model for wetland classification using Sentinel-1 and Sentinel-2
🔬 WetNet:基于Sentinel-1与Sentinel-2数据的湿地分类时空集合深度学习模型信息 👨🔬 B Hosseiny | ⏲️ 2021
具体的实验数据集的格式这里就不过多介绍,下面我们来了解一下这个“拼多多”模型的详细结构。
2. 网络结构
CVTNet 的整体架构图如下:
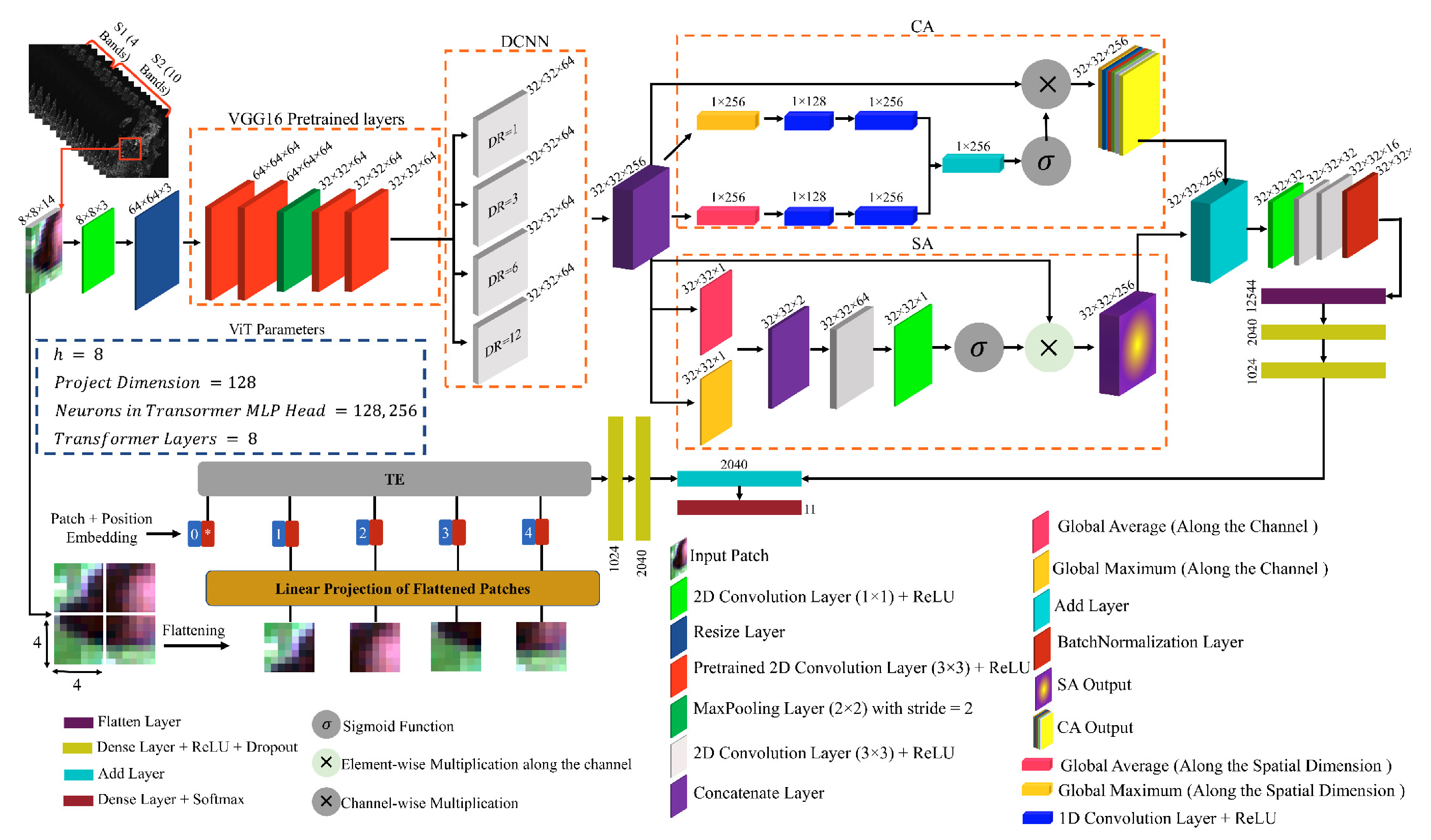
图中 ViT 分支中的
*表示额外的可学习类别嵌入([CLS]token )
从结构图中可以看出,CVNet 主要由 ViT 分支与 CNN 分支并行构成。两个分支均由现有的常用模块堆叠而成,特征融合方式也以常见的逐元素相加或通道拼接为主。因此,这里不再赘述整体流程,仅对其设计中相对值得一提的模块作简要说明。
🌟 扩张卷积
扩张卷积 | Dilated Convolution,也称 空洞卷积 | Atrous Convolution 是一种在保持卷积核参数数量不变的前提下扩大感受野的卷积方式,广泛用于语义分割、序列建模、语音处理等任务。普通卷积核在输入上是连续滑动的,而扩张卷积在卷积核元素之间插入“空洞”,让卷积在更大范围采样输入特征。
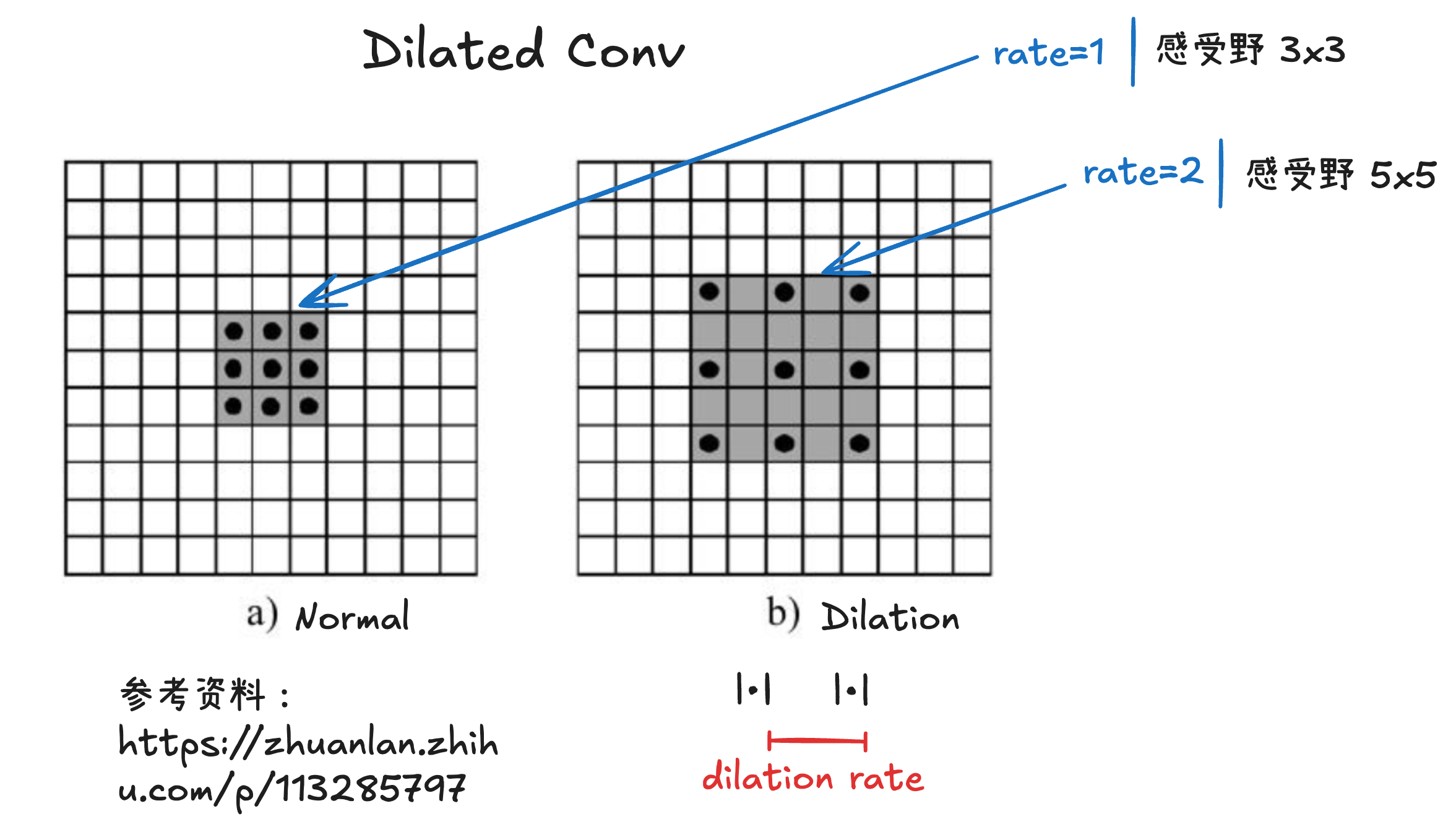
与普通卷积相比,扩张卷积的主要特点在于:
- 卷积核大小不变;
- 参数量与计算量不变;
- 通过插入空洞增加采样间隔,使卷积核在更大感受野区域内“稀疏”地采样输入特征;
- 能够在不降低特征图分辨率的前提下获取更多上下文信息。
其有效感受野大小可由以下公式给出:
其中, 为卷积核尺寸; 为扩张率(
dilation rate); 为扩张后卷积核的有效覆盖区域大小;
在实际实现时,扩张卷积并不是独立的算子,而是通过设置dilation参数直接使用torch.nn.Conv2d或Conv1d/Conv3d实现的。因此在 PyTorch 中可以像普通卷积一样构建,只需指定dilation和合适的padding。
1 | self.conv = nn.Conv2d( |
👽 空间、通道注意力
SE 通道注意力模块的结构如下图所示:
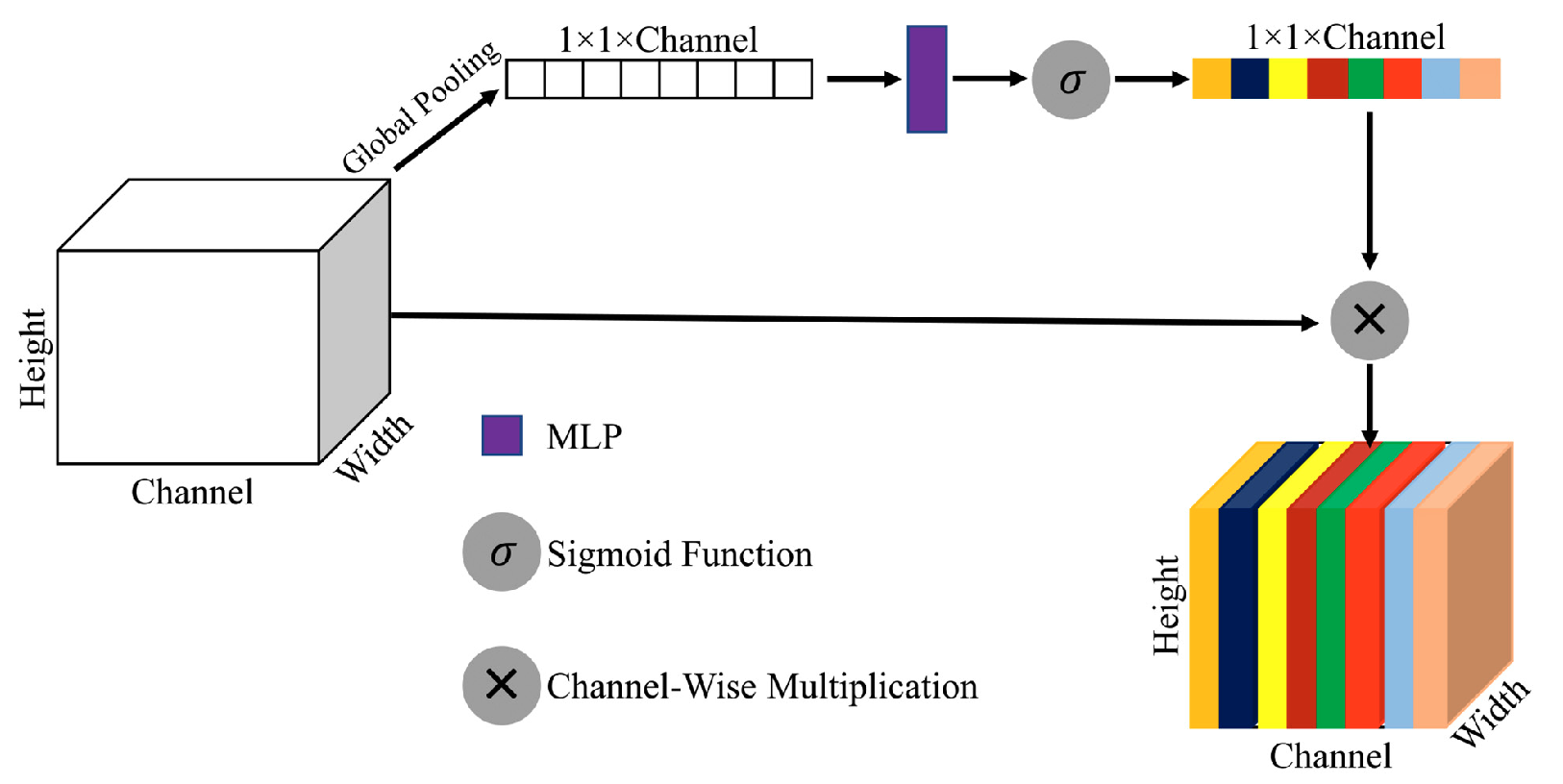
SE 模块于2018年提出,是一种轻量级且强有力的通道注意力机制。其核心思想是通过显式建模不同通道之间的依赖关系,为重要通道分配更高权重,从而提升特征表达能力。SE 模块来源于以下经典论文:
| 属性 | 详细信息 |
|---|---|
| 论文 | 🔬 Squeeze-and-excitation networks |👨🔬 J Hu |⏲️ 2018 |
该模块主要包含两个步骤:
全局信息压缩(
Squeeze):利用全局平均池化将空间维度的信息压缩为单个全局描述子,实现跨空间的全局感受。通道特征重标定(
Excitation):通过一个由两层全连接层构成的瓶颈结构(带非线性激活),生成与通道数一致的注意力权重向量,并通过逐通道缩放对输入特征进行重标定。
在 CVNet 中,SE 通道注意力模块在生成通道注意力向量的过程中进行了改进:它采用双分支设计分别提取两个独立的通道注意力向量,随后对它们进行逐元素相加融合,得到最终用于 Excitation 的通道权重向量。
原论文中使用的空间注意力模块似乎未给出明确的引用来源,但从结构上看,它可以被视为将 SE 模块中针对空间维度的 Squeeze 操作迁移到「通道维度」,从而生成空间方向的注意力图。
3. 其他
文中除了针对网络结构的描述,还有如下一些较为重要的内容:
😀 实验设置
CVNet 采用 K 折交叉验证(K-fold Cross-Validation)作为训练策略。由于不同数据集的组织方式不同,目前在实际使用中存在多种训练流程。本文介绍的训练流程如下:
首先,将完整数据集预先划分为 训练集 | train set 与 测试集 | test set。在此基础上,再分别对训练集和测试集进行 K 折切分,从而构造出 K 组彼此不同的训练/测试划分方案。在每一折的训练过程中,会对该折对应的训练子集继续按 的比例划分为训练集与 验证集 | validation set ,用于模型训练与模型选择。
这里需要特别说明的是,由于在执行 K 折之前,训练集与测试集已经完全分离,因此 所有折中的训练样本与测试样本始终保持不混淆。换言之,跨折不会发生训练集“泄露”到测试集的情况。这里实验设计的目的更多的是,让训练集内部在不同折之间形成更多的训练–验证组合,以提升模型的稳定性与泛化能力。
这里顺便也提一下k-fold与repeated k-fold交叉验证的主要区别:
| 特性 | K-fold | Repeated K-fold |
|---|---|---|
| 是否随机重新划分数据 | ❌ 只划分 1 次 | ✅ 每次 K 折都重新划分 |
| 循环次数 | ||
| 用途 | 快速估计模型性能 | 在数据量少或模型评估不稳定时获得更可靠估计 |
📼 ViT可视化
本文还参考了其他研究,对 ViT 的图像遮挡敏感性进行了分析。整个敏感度热力图的生成流程如下:
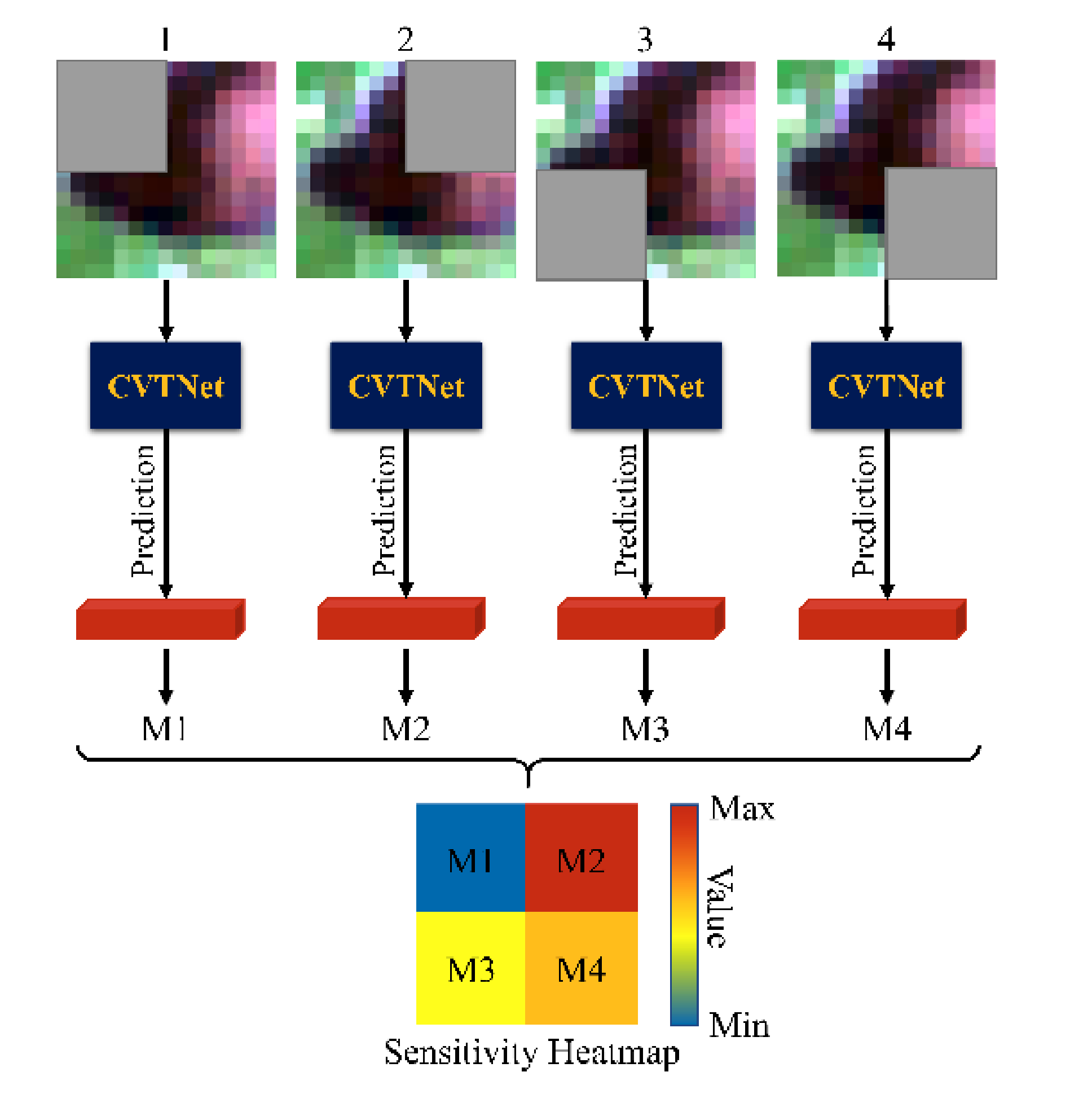
具体流程如下:
选择目标区域:确定要分析的图像区域(通常以 patch 为单位)。
应用掩膜:对目标区域进行遮挡,例如将该区域的像素全部置为0(应该可以选择其他掩码方式)。
模型前向推理:将掩膜后的图像输入 ViT 模型,获取模型输出的概率分布。
生成热力图:将该区域对应的输出概率作为热力图的值,从而量化模型对该区域的敏感程度。
通过这种方法生成的热力图,能够直观反映模型关注的 patch 在图像中的分布,从而帮助分析模型的可解释性与特征提取能力。换言之,被赋予高热力值的区域就是模型认为最重要的部分,这也有助于我们理解 ViT 在视觉任务中如何分配注意力。


