本文内容来源于网络博客及GPT生成内容,作者并未详细阅读论文原文
Transformer
1. 论文信息
| 属性 | 详细信息 |
|---|---|
| 标题 | 🔬 Attention is All you Need 🔬 注意力是你所需的一切 |
| 会议 | 📚 Advances In Neural Information Processing Systems (NeurIPS) 🏆 CCF-A |
| 日期 | ⏲️ 2017 |
| 作者 | 👨🔬 Ashish Vaswani |
Transformer模型在2017年由Vaswani等人首次提出,是自然语言处理乃至更广泛序列建模任务中的基础架构。该论文中首先提出使用Transformer处理机器翻译任务,这是一种典型的 Seq2seq 任务,其中的Transformer也是一个典型的 encoder-decoder 架构模型,其模型结构如下:
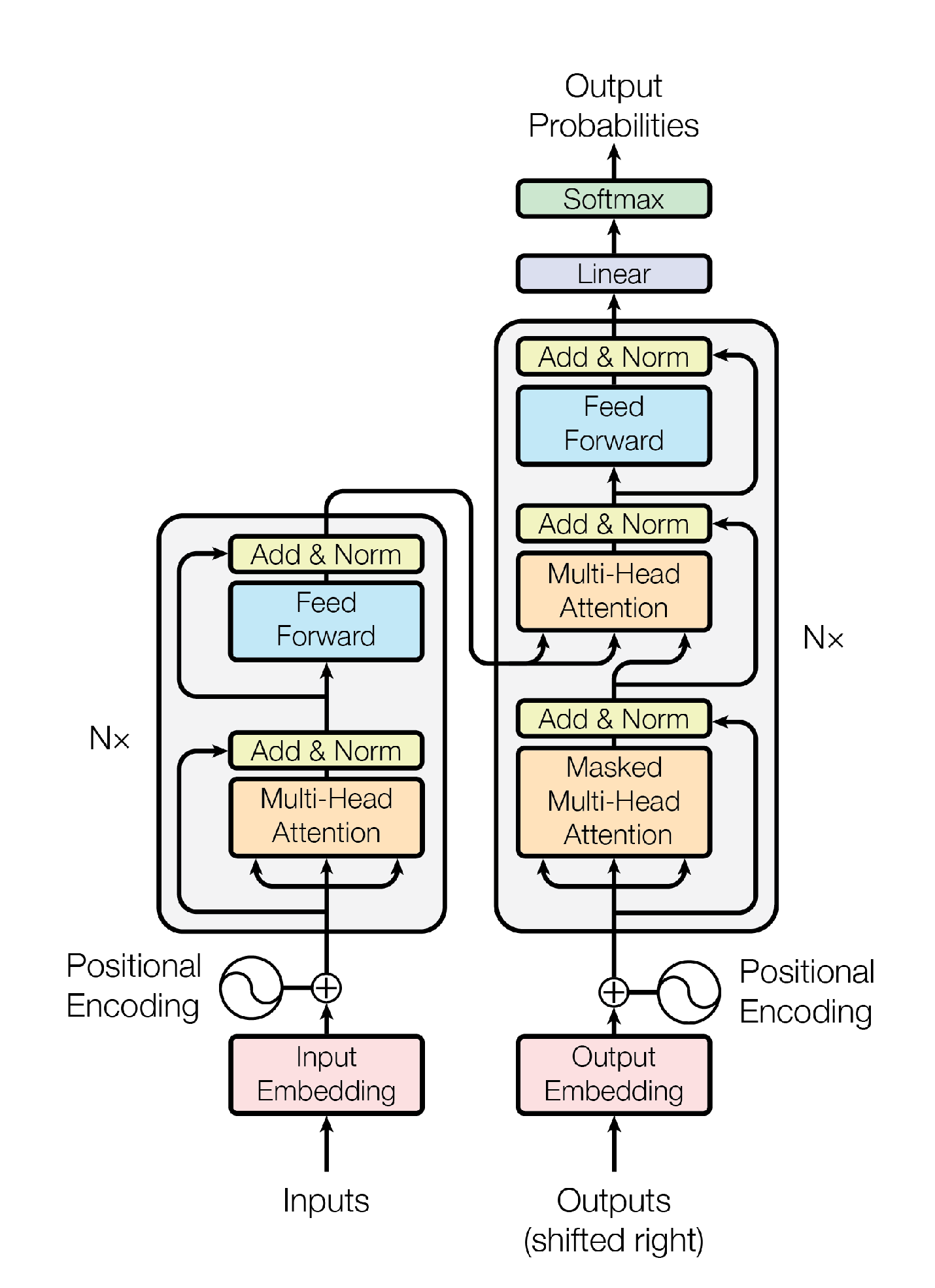
2. 嵌入与位置编码
输入嵌入 | Input Embedding 是Transformer的第一个模块,其负责将原始数据(文本、图像)变为模型能处理的向量序列。如果我们仔细观察模型架构,不难发现 输出嵌入 | Output Embedding 同样是一个不容忽视的环节。简单来说,输出嵌入就是把Transformer最后一层的输出特征,转化成下游任务真正需要的结果形式。不同任务的结果差别很大,所以输出嵌入会根据场景变化。
在了解各类任务中Transformer输入模块是如何设置之前,我们先来了解下经典Transformer的输入模块的工作原理。在开始介绍之前,我们先了解一下等下会用到的符号含义:
| 符号 | 说明 |
|---|---|
| 词汇表大小(Transformer输入和生成的值均在其中) | |
| 嵌入向量维度,嵌入向量间可以用运算表示原词语间关系(需训练) | |
| 编码器输入序列长度,词嵌入前的输入序列为: |
|
解码器目标序列长度,训练时在Output Embedding中输入目标序列 用于训练。(推理为自回归推理) |
|
| 输入嵌入矩阵,第 行是 的向量 | |
| 输出嵌入矩阵(解码器) | |
| 输出投影矩阵,常见做法是与 权重共享 | |
| Transformer层数 | |
| 、 |
多头注意力模块头数,每头维度为 |
经典Transformer处理的是文本任务,这要求我们将文本输入到编码器前要进行 词嵌入 | Word Embedding 操作。经典Transformer采用词嵌入矩阵来将离散的符号(单词或 token id )转换为可参与计算的连续向量表示,并且该矩阵是一个 可训练参数 。
现有一个嵌入矩阵 ,假设一个句子被 tokenizer 切分成为内容为 token id 的序列(这些 token id 均在词表中)。我们可以通过查找嵌入矩阵中对应ID的行向量,得到输入Transformer的矩阵。这个过程可以用如下公式表示:
这个过程实际上是可以看作一个矩阵乘法的特殊情况,如果把 token id 序列表示为one-hot矩阵,那么词嵌入过程可以表示为: ,但实际中 查表 | lookup table 更为高效。
由于自注意力机制本身并不含顺序/空间信息,Transformer还需要给词嵌入向量添加位置编码 | Position Encoding 。观察Transformer模型架构图不难发现,位置编码要与词嵌入矩阵进行相加操作,这说明两者形状相同。这里只介绍原论文中使用的正弦余弦编码:
其中, 表示输入矩阵中各词嵌入的位置索引(0开始计数),而 则与词嵌入向量的维度 有关。假设有一个词嵌入向量 ,它在输入的序列中处于第 位,它的位置编码则为:
最终将对应的初始词嵌入向量与位置编码相加,得到最终嵌入向量:
这里的 表示编码器第0层的输入,输入的矩阵为所有 组合的矩阵 。需要注意,原论文中会把初始嵌入乘以 。
Similarly to other sequence transduction models, we use learned embeddings to convert the input tokens and output tokens to vectors of dimension . We also use the usual learned linear transformation and softmax function to convert the decoder output to predicted next-token probabilities. In our model, we share the same weight matrix between the two embedding layers and the pre-softmax linear transformation, similar to [24]. In the embedding layers, we multiply those weights by .
与其他序列转换模型类似,我们使用学习得到的嵌入向量将输入token和输出token转换为维度为 的向量。我们还使用常规的学习到的线性变换和softmax函数,将解码器输出转换为预测的下一个token概率。在我们的模型中,我们共享两个嵌入层和预softmax线性变换之间的权重矩阵,类似于[24]。在嵌入层中,我们将这些权重乘以。
解码器的输入部分也有类似处理。假设训练时输入解码器的序列为 ,第 个位置的编码器输入为:
需要注意的是,在对输入序列进行词嵌入操作时,需要添加<sos>标识序列开始,这是为了在进行自回归推理时,第一步有输入。同样,训练时的解码器输出序列的末尾需用<eos>标识,用于终止自回归输出。
3. 编码器 & 解码器
编码器和解码器是Transformer架构的核心模块,而它们之所以能够高效捕捉序列中元素之间的关系,关键就在于注意力机制的引入。在深入解析编码器和解码器的整体结构之前,我们不妨先从注意力机制本身出发,理解它是如何工作的。
🦖 注意力机制
注意力机制可以理解为:我们已知属性对间存在关联,这时输入其中一个属性求另一个属性。我们可以通过计算输入属性与已知属性间的关联性得出相似性权重,再对已知的待求属性集合进行加权求和得到预测结果。过程如下图所示:
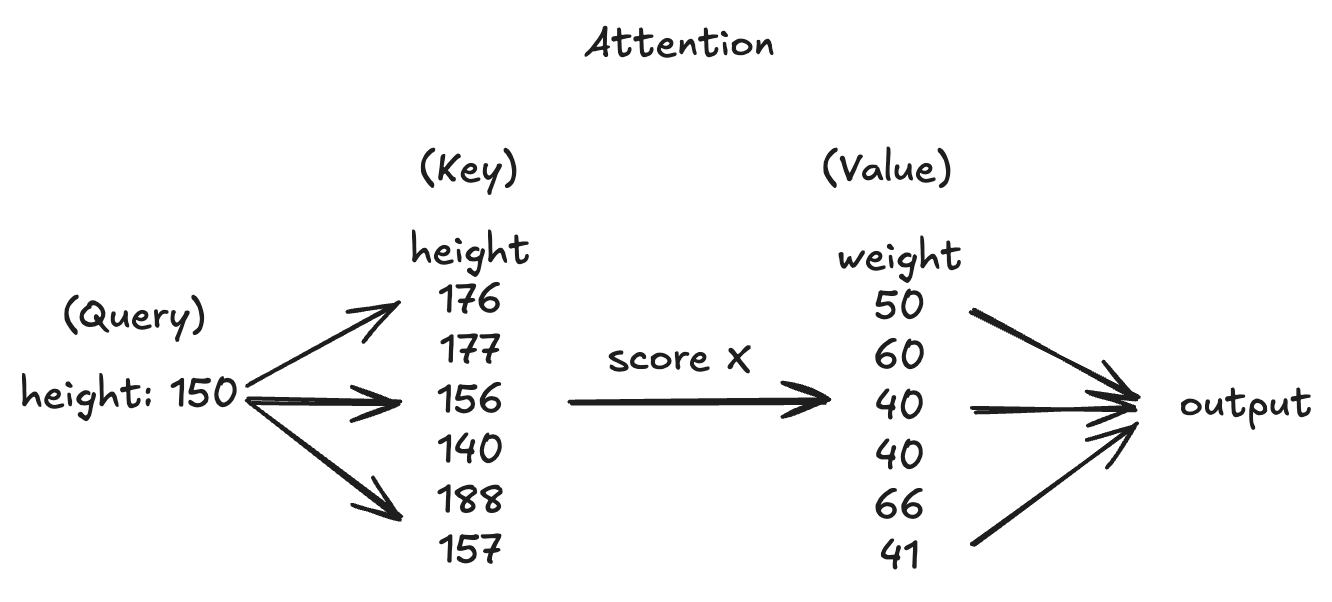
当然 可以不止有一个属性,当面对多个属性时,我们只需扩展权重即可。这时我们便顺理成章的将向量引入了注意力机制。向量可以看作对某一对象的属性描述集合 。此外,在上述例子中我们可以发现, 与 之间存在着一定的相关性,那么如果有多个属性时,的属性个数应当一致。
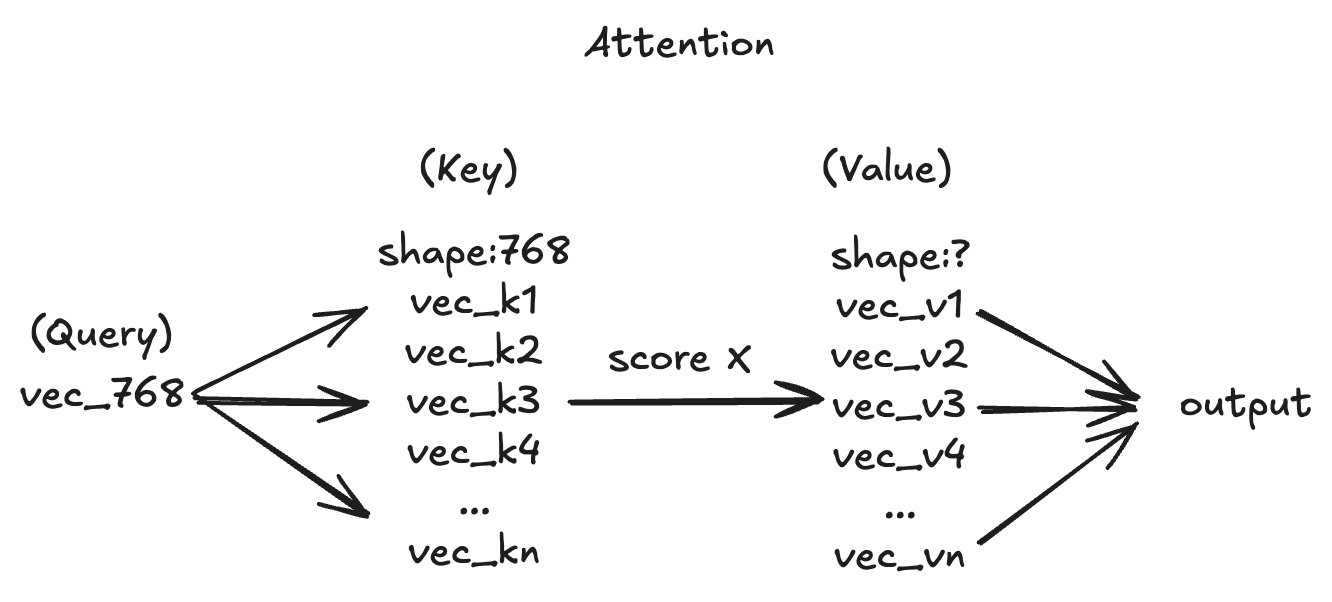
我们可以使用余弦相似度来计算 与 之间的相关性(两个 维向量在对应维度空间下的夹角的余弦可以较好的反应其相似性)。标准的Transformer使用点积代替了余弦相似度计算相似性权重:
使用点积代替余弦相似度的原因如下:
- 计算效率高:矩阵点积可以直接通过高效的矩阵乘法实现
- 可学习性更好:点积让网络自由学习模长()的重要性,而余弦相似度隐含了对模长的抑制
通过上述计算得到的结果 的过程可以被看作我们在知识库(Key-Value对)中提取出与 相关的重要信息。
🐊 自注意力机制
在注意力机制中,我们不难看出 分别代表不同的东西。但 如果为同一个输入序列时会发生什么呢?这便引出了 自注意力机制 | Self-Attention 。自注意力机制的核心思想是:在处理一组输入序列时,让每一个元素都能与整个序列中的其他元素建立联系,从而提取出与自身相关的上下文信息。
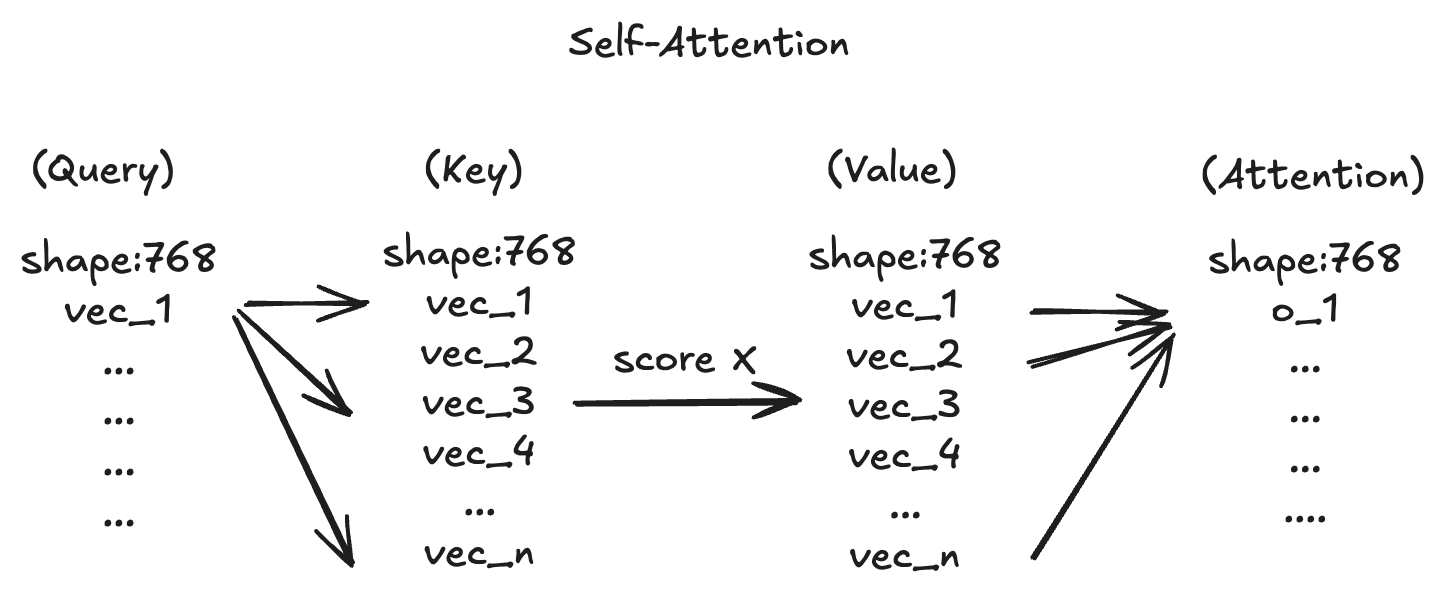
上述计算过程已经能很好的实现一个序列的信息聚合,但其并没有可训练参数的介入,这就意味着最终的输出结果比较依赖其前置步骤(例如:自然语言处理中的embeding过程)。我们可以对序列到 输入的过程中分别加入一个线性变换,使得神经网络可以学习序列中较为重要的部分。
假设输入序列为 ,那么对应的 为:
其中,,。在实际的神经网络中,变换前后的序列向量长度可以不一致,但为保证输入序列的信息不会丢失,单头注意力机制中 。对应的注意力分数计算如下:
这里的 是 缩放点积注意力 | Scaled Dot-Product Attention 的核心操作。如果不加缩放,随着维度 增大, 的点积值会变得很大:
- 一方面,过大的数值容易在计算
softmax时造成数值溢出; - 另一方面,
softmax的输出会过度集中在少数几个最大值上,导致注意力分布极端化,大部分位置的权重几乎为 0,从而丢失有效信息。
因此,在计算前我们引入 的缩放因子,用来稳定数值范围,让注意力分布更均衡、更容易训练。至于为什么选择 作为缩放尺度,这里就不展开讨论。
从矩阵运算的角度来看,每一个位置的向量都通过与其他所有位置的交互重新编码自己,这一过程自然地建模了序列内部的依赖关系。
🐲 多头注意力机制
虽然单头注意力已经具备捕捉信息之间关系的能力,但在实际任务中,我们往往希望模型能从多个表示子空间中并行学习不同的语义特征。于是,多头注意力机制 | Multi-Head Attention 应运而生。多头机制的核心思想是:将输入分别映射到多个不同的子空间中进行注意力计算,再将各头的结果拼接起来综合表达信息。
具体地,对于输入 ,我们定义 个不同的投影矩阵组 ,每个头独立执行自注意力,然后将所有头的输出拼接后,再乘以一个输出变换矩阵 融合所有头的输出。最终结果为:
其中, ,各权重系数矩阵与对应的 的尺寸如下:
| 权重矩阵 | 形状 | 变量 | 形状 |
|---|---|---|---|
综上,多头注意力矩阵拼接后的尺寸为 。此外,我们还需要一个矩阵来融合多个头提取的学习,该融合矩阵尺寸为 。
这里演示的是多头自注意力,多头同样可以应用于普通注意力机制。
⚙️ 编码器、解码器结构
由架构总览图不难看出,Transformer的编码器单元主要由 多头自注意力模块 | MHSA 、前馈网络 | FFN 构成,并穿插LayerNorm和残差连接,第 层编码器可由如下公式表示:
上述公式要点有:
- 表示第 层编码器输出,公式中 表示跳跃连接(残差)
LayerNorm层对每个 token 的特征向量进行独立归一化操作FFN层为模型提供非线性特征转换能力,由两层全连接层构成:
最后编码器输出为:
相比之下,Transformer的解码器单元就复杂许多,第 层解码器可由如下公式表示:
解码器中使用了两种注意力机制:掩码多头自注意力 | MaskedMHSA 、多头注意力 | MHAtt 。我们按顺序来学习这些模块的内部结构。
在传统的自注意力机制中,我们使用 来计算各 token 间的注意力分数,用于查找并提取与当前 token 相关的全局信息。在训练时我们当然知道输出的序列的全部信息,但在推理时我们只能对输出结果进行迭代输入得到最终输出序列(自回归)。在第 时间刻,我们只能知道之前的序列信息,因此只能提取第 刻之前的全局信息。
为了使模型在训练和推理时保持一致,解码器单元需使用掩码多头自注意力学习不同时间刻下输出序列的特征,我们为 加上一个掩盖右上角内容的掩码,这样每个时间刻的注意力向量只与之前时间刻的全局信息有关,从而得以训练出满足自回归推理的模型。
在实际代码中,我们一般使用注意力分数加上一个 矩阵实现因果掩码:
其中, 为一个右上角值 的上三角矩阵。由于 的计算原理,实际上当前时间刻注意力向量与之后时间刻的输入向量均无关(因为对应归一化注意力分数为0)。整个注意力计算过程如下:
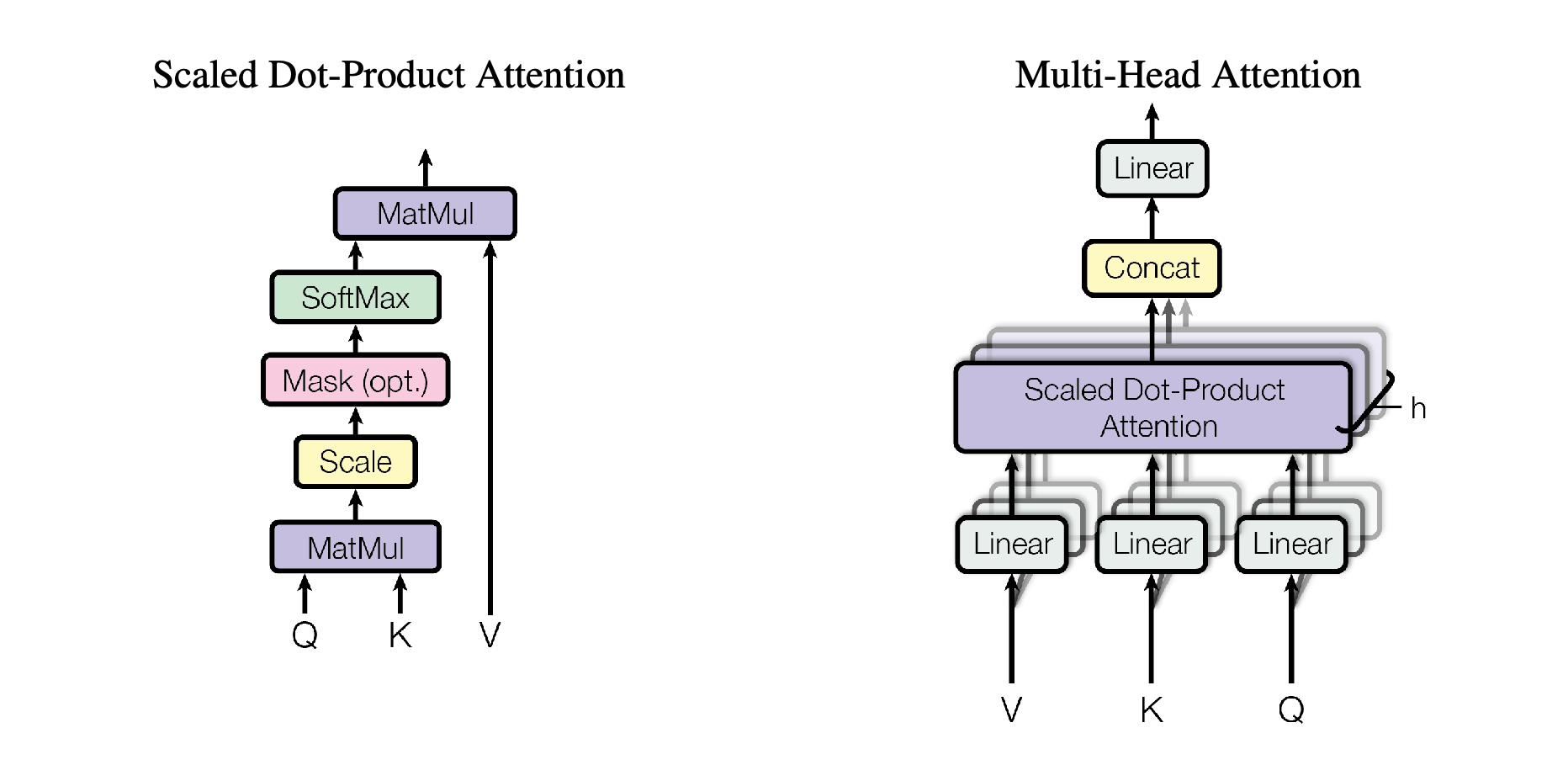
此外,Transformer的解码器还使用最后一个编码器单元的输出作为知识库(Key-Value),提取注意力向量。我的理解是,该步骤是模型从输入序列中学习如何生成输出序列的关键。下面我们来详细了解一下 的计算过程。
在单头注意力机制中,我们采用一个权重矩阵 添加可学习参数,而多头注意力中,我们采用多个权重矩阵 添加可学习参数,但无论经过权重矩阵变换后的 向量的维度如何变化,这都不会影响注意力分数的尺寸。因此,在讨论 时,我们可以把它 当作单头注意力 去观察内部计算。
该模块可以被抽象为 函数,我们通过在其内部为 添加权重矩阵实现该模块的学习能力。对于 有:
计算 间的注意力权重:
计算交叉注意力矩阵:
最后将各头输出注意力矩阵进行拼接、融合,得到尺寸为 的注意矩阵,实现了 的 Seq2seq 输出。
最后解码器输出为:
4. 输出模块
最后我们使用线性变换,将输出序列中的每一个向量映射为词表的logits从而得到最终的输出结果。以时间刻 的输出向量 为例:
其中, 就是 对应的logits向量,经过 我们可以得到该向量对应词表中的词,从而实现文本的 Seq2seq 任务。需要注意的是,我们一般会将 与 进行 权重共享 | weight typing ,即 。
经典Transformer的设计初衷是解决 Seq2Seq 类型任务(训练集同样为序列到序列),这与我的研究重点并不完全一致,因此在本节中不再深入讨论其训练与评估方法。下面,我们将继续探索在此基础上演化出的多种变体,以及它们在更广泛任务中的应用。
Vision Transformer
1. 论文信息
| 属性 | 详细信息 |
|---|---|
| 标题 | 🔬 An image is worth 16x16 words: Transformers for image recognition at scale 🔬 一张图片抵得上16×16个字:用于大规模图像识别的Transformer模型 |
| 会议 | 📚 International Conference on Learning Representations (ICLR) |
| 日期 | ⏲️ 2020(2021) |
| 作者 | 👨🔬 Alexey Dosovitskiy |
Vision Transformer(ViT) 是2020年Google团队提出的将Transformer应用在图像分类的模型,虽然不是第一篇将Transformer应用在视觉任务的论文,但是因为其模型简单且效果好,可扩展性强,成为了Transformer在计算机视觉(CV)领域应用的里程碑著作。关于该论文的详尽解读,可参考「ViT解析 - 德怀特」这篇博客,这里就不过多介绍论文细节。接下来我将着重介绍模型结构以及阅读相关论文、博客时产生的疑问。
2. 模型结构
ViT将一幅图像分割为多个patch,再将每个patch拉伸后投影到固定长度的向量,这样就将一幅图像转化为了Transformer可以处理的 tokon 序列。ViT的模型结构如下:
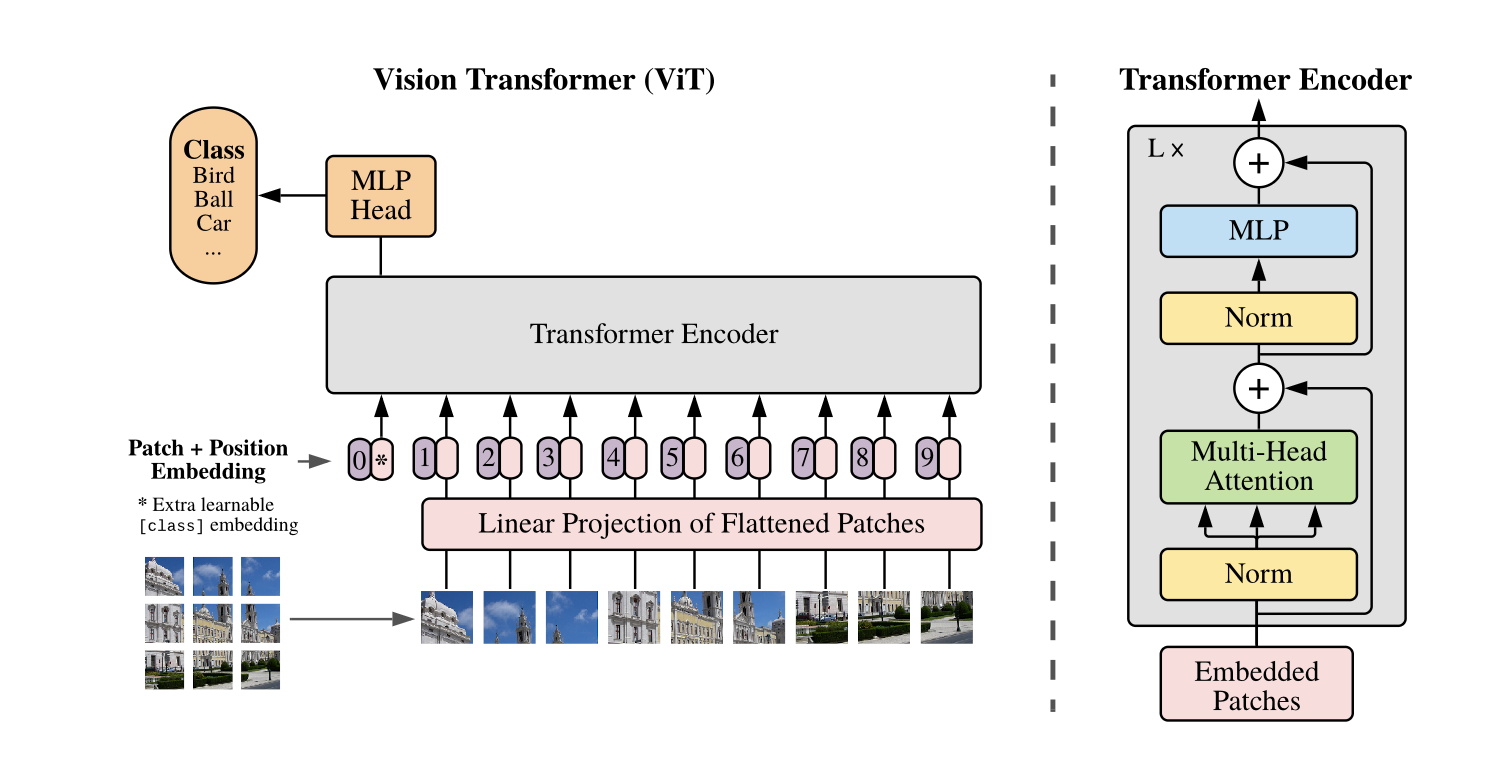
下面我们通过数学公式,了解一下ViT的内部结构。我们先来了解一下接下来会用到的符号含义:
| 符号 | 说明 |
|---|---|
| 输入影像(论文中为 ) | |
patch大小(论文中为 ) |
|
patch网格大小 |
|
不含[CLS]的patch数 |
|
| Transformer接受的 token 数 | |
| 单个 token 维度,也可用 表示 | |
| 多头注意力机制头数,每头内部的 embed 维度为 |
🛷 图像序列化
ViT会将输入图像按 切分成为 个patch,并将每个patch进行展开与线性投影,即 图像块嵌入 | patch embedding 。
ViT首先将每个patch按一定维度顺序展开成为一维向量 。这时我们得到了一个长为 的 patch token 序列。与处理文本任务时相同,我们在将该 token 序列时也需要进行嵌入操作,将 token 向量转化为 维度向量:
我们不妨回忆一下Transformer中为何要在输入模块中进行“词嵌入”操作,那是为了使得每个 token 间的语义关系可以用词嵌入向量表示,从而方便后续注意力计算。而ViT在这里使用线性投影将原拉伸向量投影到embedding维度,则可被看作进行了一次浅层特征提取,该步骤提取了patch的纹理、颜色、边缘等特征(嵌入向量维度可看作特征数)同样用于后续的注意力计算。
原论文中该步骤公式为:
(这里的 即 )
ViT原论文嵌入操作的相关公式并未使用偏置项,但其源码的
Linear默认bias=True,因此实际上是使用了偏置项的。此外,一些博客中也会直接使用全连接层的公式()表示嵌入操作。加入偏执项会增加嵌入层的表达能力(学习能力)。但需要注意的是,在嵌入操作后紧接位置编码和
LayerNorm,这可能减少偏置项的作用。对大规模模型和大数据集来说,加不加偏置通常影响不大。
我们已经计算得到了 ,但这个序列中每个 patch token 都只是对应patch中的局部信息,我们还需要一种方法在模型中提取全局信息。受BERT的启发,ViT引入 ,这是一个可学习的全局聚合 token ,在ViT的编码器中,它通过自注意力机制与所有的 patch token 交互,从而收集到整张图的全局信息。
综上最终ViT输入到Transformer编码器的数据如下:
ViT实现图片分类实际上就是使用 通过多层Transformer编码器单元,输出一个聚合了全局信息的特征嵌入向量 ,然后使用MLP将该嵌入向量映射为用于分类的logits(),从而实现图片分类:
需要注意的是, 在训练和推理时始终唯一。在训练时 会初始一个向量用于训练,这个向量与图像标签无关,图像标签仅参与模型输出的误差计算。在推理时,ViT则使用训练得出的 提取 patch token 中的特征。
除了使用Transformer的encoder提取用于分类的logits,其实还可以直接使用 patch token 输出分类logits,这种情况下,我们不需要在ViT的输入序列中加入可训练向量 。这里简单介绍一下两种 ViT without CLS token 的实现:
平均池化:对Transformer编码器最后一层的所有 patch token 输出取均值,如何送入分类头:
加权池化:用一个可学习的权重向量 对所有 patch token
拼接+
MLP不常用:把所有 patch token 输出拼起来(或取部分 token),输入一个MLP再得到分类特征
🧐 注意力可视化
原论文中还使用注意力可视化图说明模型关注的是与分类语义相关的图像区域,我想在这里探讨一下这种注意力heatmap图是如何绘制的。

这种图实际上就是可视化了[CLS]对应 token 对所有 patch token 的注意力分数。分数越高说明[CLS]对这个地方的patch关注度越高,ViT就更倾向于提取这些区域对应 token 的特征。
ViT的Transformer编码器单元中使用了多头自注意力机制为每个 token 提取并融合全局特征,其中第 个头的注意力分数矩阵由如下公式计算:
我们找到[CLS]对各patch的注意力分数向量,即:
其中,注意力矩阵的角标需要解释一下。由于[CLS]是第0位 token 因此我们取第0行注意力矩阵。此外,我们在可视化时不考虑[CLS]对其自身的相关性,因此截取 的注意力分数用于可视化。多头注意力分数的可视化方法有多种,这里我们选取去多头平均值的方法合成最终用于可视化注意力向量 :
又由于 我们可以将 中各元素重塑到各patch在原图中位置,然后我们可以对该heatmap(14x14)插值(常用双线性插值 )到原图分辨率,得到最终的注意力heatmap(224x224):
🌍 位置编码
ViT就位置编码做了消融实验,在介绍该实验前我们先逐步了解一下视觉任务中的位置编码。
Transformer 本身没有卷积的局部归纳偏置,也没有循环网络的顺序建模能力,它把输入看作一个无序的集合,因此需要我们需要使用位置编码显式地告诉模型每个patch在图像中的位置。常见的位置编码有:
可学习(Learnable)的绝对位置编码:原版ViT(Dosovitskiy et al., 2020)就是使用这种方法。该方法初始化一个 的参数矩阵,并在训练中作为可学习参数更新。
好处:灵活,模型可以直接学习到合适的编码。
缺点:输入大小变化时不能直接用(如果位置数不同,需要进行插值处理)。
正弦位置编码:该编码方式来源于原版Transformer(Vaswani et al., 2017),该方法适用于一维和二维的位置编码。在图像中,通常会为行、列分别生成维度为 的编码,再将两者拼接在一起作为最终。
其他的编码方式还有:相对位置编码(Swin Transformer、DeiT),或者使用位置感知初始化代替位置编码
Inductive bias. We note that Vision Transformer has much less image-specific inductive bias than CNNs. In CNNs, locality, two-dimensional neighborhood structure, and translation equivariance are baked into each layer throughout the whole model. In ViT, only MLP layers are local and transla-tionally equivariant, while the self-attention layers are global. The two-dimensional neighborhood structure is used very sparingly: in the beginning of the model by cutting the image into patches and at fine-tuning time for adjusting the position embeddings for images of different resolution (as described below). Other than that, the position embeddings at initialization time carry no information about the 2D positions of the patches and all spatial relations between the patches have to be learned from scratch.
归纳偏置. 我们注意到,Vision Transformer相较于卷积神经网络(CNN)具有显著更少的图像特异性归纳偏置。在CNN中,局部性、二维邻域结构 以及 平移不变性 贯穿整个模型,嵌入到每一层中。而在ViT中,仅多层感知器(MLP)层具有局部性和平移不变性,而自注意力层则是全局的。二维邻域结构的使用非常有限:仅在模型初始阶段通过将图像分割为patch时使用,以及在微调阶段用于调整不同分辨率图像的位置嵌入(如下面所述)。除此之外,初始化时的位置嵌入不包含patch的二维位置信息,所有patch之间的空间关系都必须从头开始学习。
归纳偏置:即一种先验知识,提前做好的假设
局部性:图片上相邻的区域具有相似的特征
平移不变形:,其中 表示卷积操作, 表示平移操作。
ViT对位置编码做的消融实验结果如下,可以看出位置编码方式的不同对模型精度的影响较小。原因可能是ViT是作用于patch上的,模型对patch间相对位置信息很容易理解,所以位置编码选择对精度影响不大(或者是由于训练数据量较大,模型已经学习到了如何根据 patch token 的内在信息学习到各patch间位置关系)。

Swin Transformer
1. 论文信息
| 属性 | 详细信息 |
|---|---|
| 标题 | 🔬 Swin Transformer: Hierarchical Vision Transformer using Shifted Windows 🔬 Swin Transformer:使用移位窗口的分层视觉Transformer |
| 会议 | 📚 Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) 🏆 CCF-A |
| 日期 | ⏲️ 2021 |
| 作者 | 👨🔬 Ze Liu |
Swin Transformer 是微软团队在2021年提出的一种视觉Transformer模型,其论文也获得了当年的ICCV最佳论文。关于论文的详细讲解,可以参考「从ViT、DPT到Swin Transformer - Dezeming」、「Swin Transformer论文精读 - 李沐」这两篇解读,这里我只简单介绍一下模型的结构以及我感兴趣的内容。
2. 模型结构
在ViT中,图像仅经历一次拆分即被送入Transformer编码器进行序列化处理。对于大尺寸图像,若想避免下采样带来的信息损失,就必须显著增加输入序列长度(),这时自注意力机制的时间复杂度也会以 的速度增加。而 Swin Transformer 的解决方案是:将自注意力计算限制在局部窗口内执行,大幅降低计算量;随后通过滑动窗口(Swin,即 Shifted Window)操作,让相邻窗口进行信息交互,从而降低计算复杂度。其模型结构图如下:
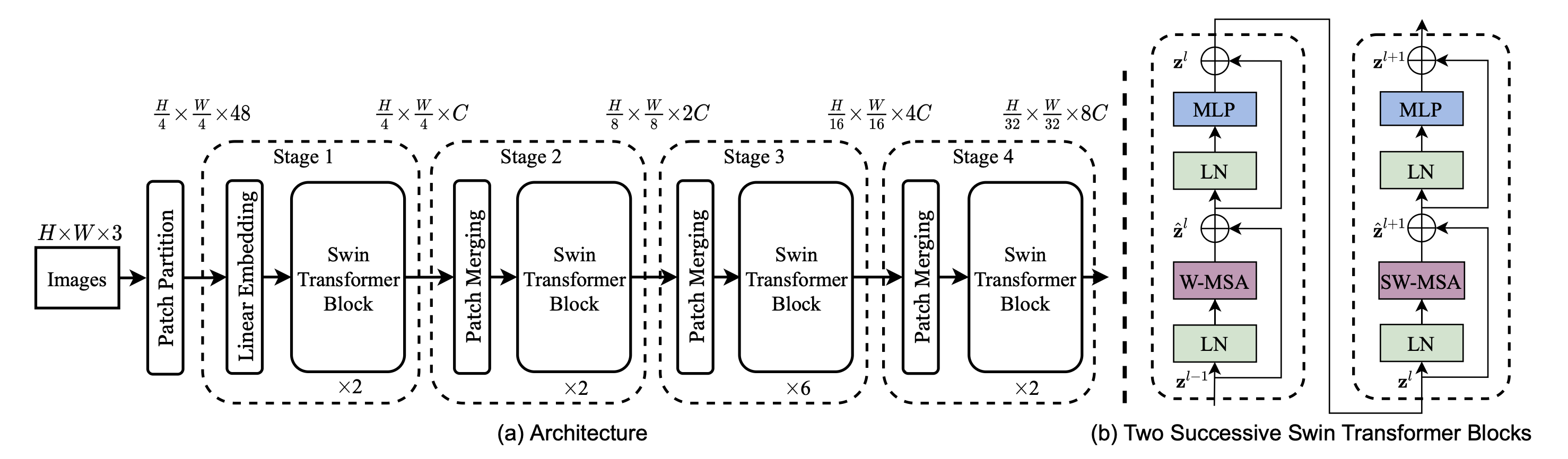
在详细了解Swin-T架构前,我们先来学习下等下会用到数学符号及其含义:
| 符号 | 说明 |
|---|---|
| 输入Swin-T的图像张量,其中 表示图片通道数。 | |
patch大小,及原图按patch切分后网格大小 |
|
token patch 序列长度(由于Swin-T没有[CLS],因此不加角标) |
|
| 即Transformer、ViT中的 、 ,表示嵌入向量维度 | |
| 多头注意力机制的头数 | |
| 窗口大小,一个窗口内有 个 patch token(论文设置为7) |
🥅 输入模块
Swin-T同ViT一样,在输入时也需要对输入图像按 大小拆分,然后对每个patch拉伸后进行嵌入操作,这对应Swin-T架构图中的 Patch Partition 与 Linear Embedding 模块:
Patch Partition 模块将图片按设置的
patch大小拆分,然后将每个patch拉伸成为一个一维向量 ,这样我们就将原图张量的维度转化为了 (即 )。Linear Embedding 模块则对每个展平后的 patch token 线性投影到 维嵌入向量,我们将 Patch Partition 的结果拉伸为一个序列 ,则 Linear Embedding 可描述为:
不难发现,上述投影过程也可以用一个
stride=P、kernel_size=P、padding=0、kernel_number=D的Conv2D实现(工程实现常用)。总之,此模块最终将输出一个嵌入空间张量 到 Swin-T Block 中,然后Swin-T会按窗口为单位将局部空间张量展开以序列的形式进行注意力计算。
在看完上述输入模块的描述后,你或许有个疑问——位置编码呢?Swin-T实际上使用ViT - 🌍 位置编码中提到的相对位置编码,这种编码的计算过程是与注意力分数计算同时进行的,下面会详细讲解编码计算过程。
🧩 Swin-T Block
Swin-T的整体架构由四个阶段构成,每个层次用于提取不同尺度特征。这里暂不讨论Swin-T多层次架构设计的优缺点是什么,我们可以根据架构图中每个阶段输出的张量尺寸推测出Swin-T Block的输入输出尺寸。由架构图可知, Swin-T Block 中的W·MSA、SW·MSA、MLP并不会改变特征张量的尺寸,这个模块仅作为 patch token 特征提取模块使用。而 Patch Merging 模块则为后续阶段中特征张量尺寸变化提供基础。接下来我们详细了解一下Swin-T Block的内部构成,在Swin-T中有两类Block:
一种Swin-T Block使用 窗口多头注意力 | W·MSA 计算自注意力,这种注意力模块会将输入的空间张量按 窗口分割输入多头注意力模块,然后在输出后的 token 序列按之前划分还原成窗口,保证输入输出结构一致。
论文中相关公式如下
由上述公式可知, 的输出与Swin-T Block输入尺寸保持一致,因此不需要线性变换就能进行残差连接。
W·MSA除了输入与ViT使用的传统MSA不同,在进行注意力计算时也有差别。以下是我的理解:
在传统的Transformer中,输入序列在进行自注意力计算前会加入位置编码,使得每个 token 不仅包含内容信息,还包含位置信息。这样在计算某一位置的 token 注意力向量时,注意力机制更倾向于关注在位置上与之临近的 token 。
为了方便理解,我们不妨假设一个极端情况:假设现有一组 token 序列,这组序列如果不加 位置信息 ,在不考虑 的参数值的情况下,所有的 token 彼此间都相似(即注意力分数相同),那么最终输出的注意力 token 便是输入序列的均值。而给 token 加上了位置编码后,相当于给 token 引入了位置差异,在计算 token 间相关性(注意力分数)时,相邻位置的相关性将大于较远位置,从而实现对序列局部信息的提取。
在上述位置编码方式中,位置信息直接加在了 token 向量所有嵌入维度中,这可能会影响原本 token 内容信息的表达。因此,Swin-T选择使用相对位置编码实现位置信息与注意力向量的融合。在相对位置编码中,位置信息不在自注意力计算前将嵌入 token 向量,这意味着,注意力分数仅与 token 间内容信息有关。然后,该方法在计算得到的注意力分数矩阵 ()的基础上,再对每个注意力加上一个与对应 token 间相对位置有关的偏移量,从而实现位置信息的嵌入。
综上,假设在Swin-T中输入自注意力机制的序列为 ,其中 表示窗口中 patch token 的个数,注意力分数矩阵的形状为 ,那么我们需要为 相对位置编码 维护一个可训练偏置矩阵 ,其中 仅由 和 在 窗口 内的相对偏移决定。由于在窗口内,token 间相对偏移的取值范围为 ,因此在Swin-T论文以及实际使用中,我们常维护一个可学习的偏置表 (其中 表示MSA头数)实现位置信息的引入。
对于窗口中两个位置 ,相对位置编码可由如下公式表示:
其中, 表示对应相对偏移值在表 中的索引。
相对位置编码 和 很好理解,但不能发现基于W·MSA模块的Swin-T Block只能在规定窗口内提取注意力向量,换句话说,该模块只对空间特征张量中的局部全局信息进行了提取,不同窗口间的信息交互只能通过MLP进行?。为了实现窗口间的信息交互,Swin-T便在W·MSA的基础上引入了 滑动窗口 构建了基于SW·MSA的Swin-T Block:
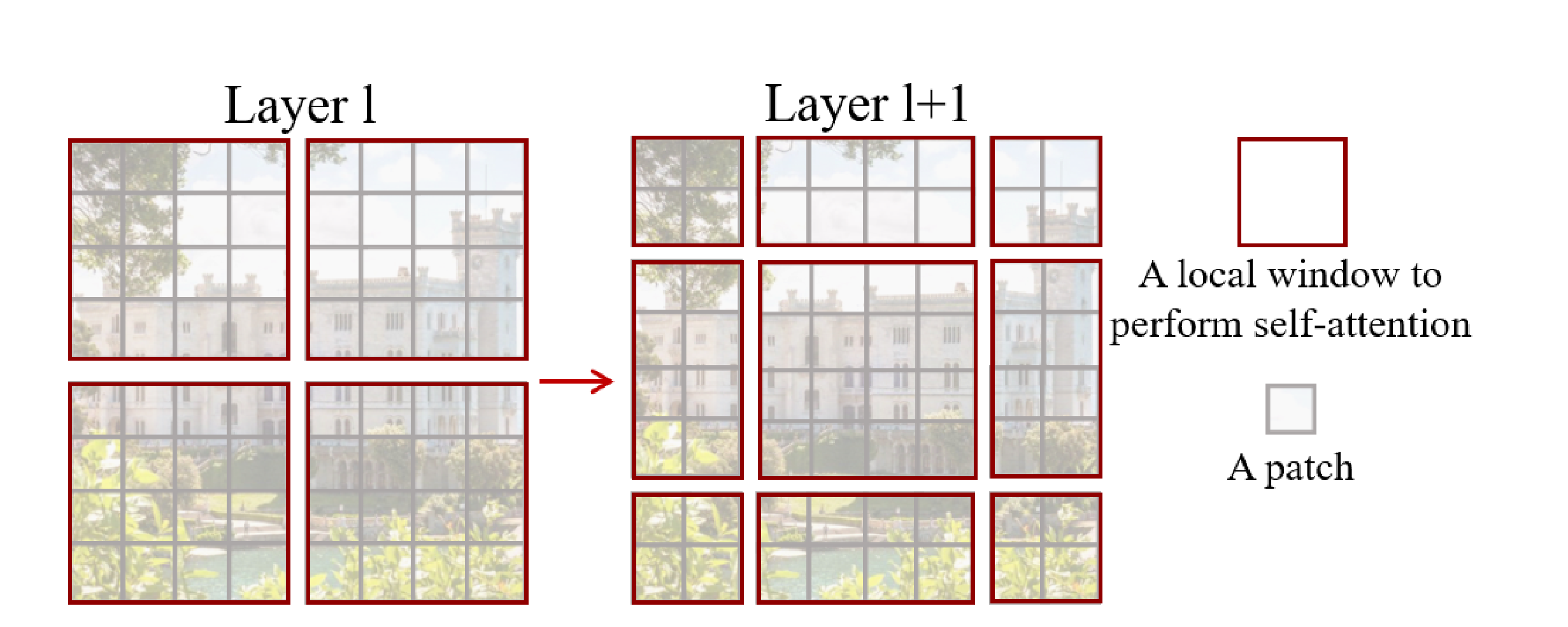
其中 Layer l 表示一层Swin-T Block,而 Layer l+1 则表示下一层Block,这说明这两种Block在Swin-T结构中是交替排列的。这正好对应了Swin-T架构图中每个阶段的Swin-T Block数目。
SW·MSA将窗口向右下平移 ,然后将原窗口内的patch按平移后窗口分割,得到新的输入窗口分割。这实际上也是在对原特征图进行平移大小为 的 循环平移 | cyclic shift :
然后我们依然按照原窗口为单位,将原窗口内的 patch token 输入到MSA中。不难发现,经过滑动窗口,整张图片的窗口数发生了变化,有些窗口内的 patch token 数也发生了变化。我们当然可以为 patch token 数不满 的窗口进行pad,从而实现输入MSA的序列长度保持一致,但增加的窗口数的的确确的影响了模型训练效率,这时我们可以采用 边缘拼接 (个人命名) + 注意力掩码 的方式减少MSA运算次数。
我们可以将 循环平移 后图像的边缘按如下方式拼接,从而使得参与MSA计算的窗口数也保持一致:
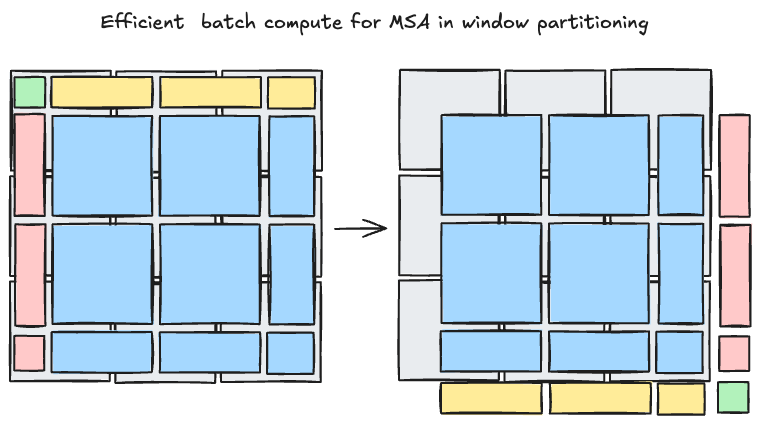
9→16→9)为了使得混合窗口在进行注意力计算时不同窗口的 patch token 不相互影响,我们还需对最后计算的到的 自注意力分数 进行掩码处理。假设在未平移时,每个 所属的窗口编号为 ,那么掩码可由如下公式构造:
如何生成掩码可以参考Swin-T在Github上的这篇issue。这里需要说明的是,Swin-T在进行以窗口为单位的MSA时生成的注意力分数矩阵为 ,由于在展开拼接窗口时,相同原窗口的序列长度常为 、、 ,所以 Issue 中的可视化结果会出现长方形、大/小正方形交替出现的情况。
综上,Swin-T通过交替使用由W·MSA、SW·MSA组成的Transformer Block,实现了图像局部特征的提取以及相邻窗口间的信息交互,能在消耗较少计算资源与参数量的情况下,有效捕捉多层次图像特征,并为后续视觉任务提供特征表示基础。
🛹 图像块合并
最后我们再来了解一下Swin-T是如何实现空间张量的下采样的。Swin-T并没有使用Pooling+Conv的方式分步骤实现下采样,而是将 相邻 patch token 拼接(concatenate)在一起,如何用一个线性层映射到新的维度(4C→2C),同时实现对输入的空间特征张量的下采样和特征融合。假设输入 patch merging 的空间张量为 ,那么该过程可由如下公式表示:
🎙️ 后话
关于Swin-T的实验部分,这里就不详细讲解了,具体内容可以去看论文原文以及参考资料中的解读视频。Swin-T这篇论文除了做了在图片分类数据集(ImageNet-1K、ImageNet-22k)上的对比实验,还做了在目标检测数据集(COCO)、语义分割数据(ADE20K)上的实验。显然,Swin-T可以做为 backbone 用在各类任务当中。
骨干网络 |
Backbone Network,即深度神经网络中主要负责特征提取的核心部分。骨干网络的作用有:
特征提取:从原始输入(图像、语音、文本等)中提取高层次的特征表示
迁移学习:许多骨干网络是在大规模数据集(如 ImageNet)上预训练好的,然后迁移到下游任务中(如目标检测、分割等)
结构基准:下游任务的性能在很大程度上依赖骨干网络的设计与能力
借物表
| 参考资料 | 说明 |
|---|---|
| Transformer模型详解 - 初识CV | 知乎文章|Transformer参考 |
| Transformer学习笔记一:位置编码 - 猛猿 | 知乎文章|Transformer参考 |
| ViT解析 - 德怀特 | 知乎文章|ViT参考 |
| 从ViT、DPT到Swin Transformer - Dezeming | 知乎文章|Swin Transformer参考 |
| Swin Transformer论文精读 - 李沐 | Bilibili视频 | Swin Transformer参考 |


