CRM:使用光学与SAR影像的作物轮作制图
1. 论文信息
| 属性 | 详细信息 |
|---|---|
| 标题 | 🔬 Mapping Crop Rotation by Using Deeply Synergistic Optical and SAR Time Series 🔬 利用深度协同光学和合成孔径雷达时间序列绘制作物轮作图 |
| 期刊 | 📚︎ Remote Sensing 🌍 地球科学2区 |
| 日期 | ⏲️ 2021-10-17 |
| 作者 | 👩🔬 Yiqing Liu |
| 关键词 | crop rotation mapping、deep learning、SAR and optical time series、dynamic feature extraction |
本文的主要内容是提出一个轮作作物制图方法(CRM)。主要考虑的作物类型的物候如下图所示:
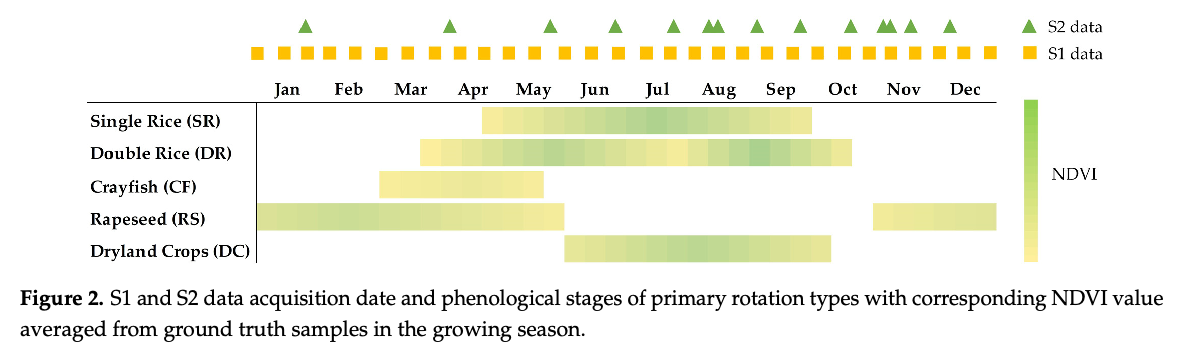
通过上述基础作物类型的组合,论文选择的分类类型为:CF-SR、F-SR、F-DR、RS-SR、RS-DC、其他轮作类型(视为一种分类类型)、水、泥滩、植被、建设用地,共10个类别。
2. 卫星与样本数据
本文使用了GEE获取的Sentinel-1/2影像(SAR影像处理略),其中光学影像的去云使用GEE的S2云概率数据集去云,并提取了NDVI、EVI、kNDVI。选择kNDVI的原因及引用如下:
while kNDVI has proven to have a higher sensitivity to vegetative biophysical and physiological parameters compared to classical vegetation indices.
与传统植被指数相比,kNDVI已被证明对植被的生物物理和生理参数具有更高的敏感性。
属性 详细内容 论文 🔬 A Unified Vegetation Index for Quantifying the Terrestrial Biosphere 其他 📚︎ Science Advances | 综合期刊1区[TOP] | 2021
这三个指数的计算方法如下:
其中, 是一个长度尺度参数,表示对植被稀疏度的敏感性。论文中设置为 。
论文使用的实验数据为通过实地调研/农民访谈获取的3年(2018-2020)作物轮作数据,总共689个地面样本。然后对谷歌地球高分影像(2018)进行目视解译,添加了201个非耕地样本。论文通过对真实样本进行样本增强(将真实样本像素的上下左右像素归位同一类型样本)最终获得4450像素的样本;
由本段内容可知,论文中样本为像素基样本。最终增强后的样本数为 。由于增强的样本与真实样本存在空间临近关系,在训练时需考虑样本标签在近邻区域聚类的问题。论文中训练时处理如下:
When feeding our models, 80% of samples were randomly selected from the ground-truth collection for training, and the rest were used for validation. To avoid accuracy uncertainty due to random training and validation split, we applied a fixed set of the shuffled dataset to all competing models, which eliminated the risk of sample labels clustering in the near neighborhood.
在训练模型时,我们从真实数据集随机选取 80% 的样本用于训练,剩余部分用于验证。为避免因随机划分训练集和验证集导致的准确率不确定性,我们对所有参比模型应用了固定的打乱数据集,从而消除了样本标签在邻近区域聚集的风险。
对于论文原文我有如下疑问:
ground-truth collection 对应论文的 2.3. Ground-Truth Data 小节,应该是指经过样本增强后的数据。对比实验中都采用同一打乱顺序的数据集是否可以消除样本临近聚类的风险存疑(都有影响 = 都没影响🤨)?
3. 网络结构
CRM网络的总体任务是接收时序光学指数、SAR数据,输出一个像素基分类结果,网络结构如下图所示:
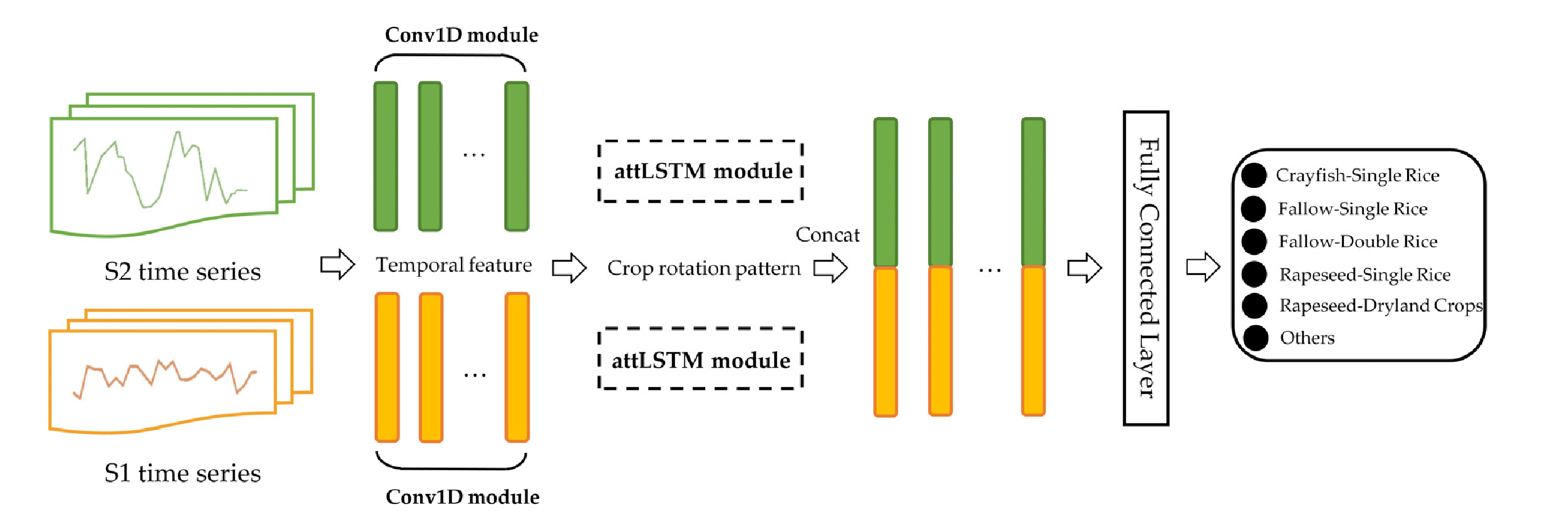
CRM的两个分支采用相同的处理模块,然后将处理后的时序特征按对应时间点拼接后放入全连接层中。下面我们详细了解一下该网络的各个模块。
🕙 时序特征提取模块
论文中将CRM网络中处理光学/SAR特征的模块成为 流 | stream ,将这两个模块称为 双流 | dual-stream 。GPT告诉我这两种称呼近乎等价,但stream强调的是两个并行模块的输入特征的异质性,而branch则强调这两个模块在网络结构上的分支关系,不同分支可能用于提取同一输入的不同特征,然后融合结果。
CRM采用两个相同的模块分别处理光学/SAR时序数据,其首先使用两层 一维卷积 | Conv1D 提取时序特征,一维卷积层公式如下:
其中, 表示卷积核, 表示卷积核数量, 表示偏置项(论文中加号错写为等号), 表示通道数, 表示激活函数, 表示卷积运算。
上述内容是论文原文中的解释,下面讲讲我的理解。公式中的 是指卷积层所在层的层数,而 表示当前卷积层的第 个输出通道。整个公式的意思是,卷积层的输出通道 的结果是对所有输入通道 做卷积并加权求和,加上偏置后再通过激活函数。
Conv1D和Conv2D是CNN中两种常用的卷积操作,它们的主要区别在于输入数据的维度和卷积核的移动方式。
- 一维卷积用于处理序列数据,输入形状为:
(batch_size, sequence_length, channels)。卷积核是在“序列长度”这个维度上滑动,用于提取局部序列特征。(注意不是1x1 Conv2D)- 二维卷积用于处理图像数据,输入形状为:
(batch_size, height, width, channels)。卷积核用于提取局部图像特征。
CRM的卷积模块具体设置为:
- 先用小卷积的
Conv1D提取局部细节 - 再接
Dropout防止过拟合 - 然后再用大卷积核的
Conv1D提取全局特征 - 最后接
MaxPooling减少特征维度(对一维数据池化,减少时序长度🤨?)
这部分模块的设计参考了如下论文的工作,我的理解是CRM使用此模块代替传统的时序滤波操作(论文没有提及如何补全去云后的S2影像数据)。
This operation was inspired by recent work [28], which successfully showed that the one-dimensional convolutional deep learning framework was capable of extracting effective and hierarchical features layer by layer in multi-temporal classification tasks.
此操作受近期研究启发[28],该研究成功证明了一维卷积深度学习框架在多时相分类任务中能够逐层提取有效且分层的特征。
属性 详细内容 论文 🔬 Deep Learning Based Multi-Temporal Crop Classification 其他 📚︎ Remote Sensing of Environment | 地球科学1区[TOP] | 2019 | 1000+
🗒️ attLSTM模块
经过上述的时序特征提取模块,CRM已经提取了 健壮时间特征 。接着,CRM使用带有注意力机制的LSTM处理这些特征。论文中虽没明确讲解该LSTM模块是什么结构,但根据给出的CRM总览图可猜测其为 Seq2seq 的结构。适用于 Seq2seq 的注意力机制有 Bahdanau attention 、Luong Attention 等。论文中中虽没给出attLSTM的结构,但引用了Luong的论文,可能使用的是使用 Luong Attention 的LSTM。下面我们来了解一下这些注意力机制。
传统的 Seq2seq 架构是先用encoder将输入序列编码称为一个context向量,decoder将context作为初始 隐状态 | hidden state ,生成输出序列。这个过程可以参考下图:
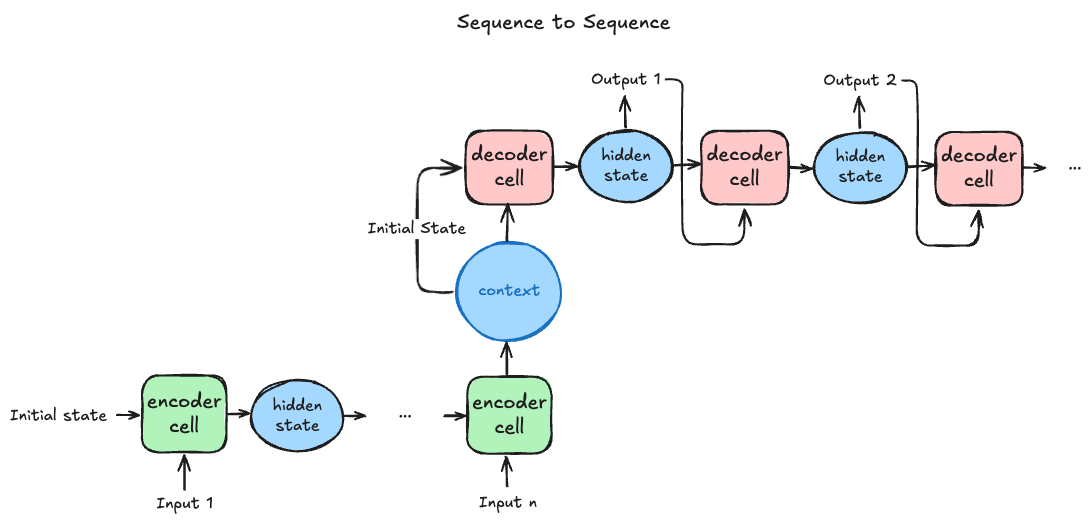
需要注意的是,decoder单元输出的隐状态既作为当前单元的输出,也作为下一个单元的输入(encoder、decoder的单元结构需保持一致)。由于decoder单元的隐状态和输入一致,在其他版本的架构图中,也可省略decoder单元的输入表示。
随着序列长度 增加,编码器难以将所有输入学习编码为单一context向量,难以从输入序列中提取重要特征,这时便需要引入适用于 Seq2seq 架构的注意力机制来解决这个问题。
首先介绍 Bahdanau Attention 机制,这是由Bahdanau在2014提出的一种适用于 Seq2seq 架构的加性注意力机制(注意力分数为加性计算)。其公式如下:
第一个公式中各参数尺寸如下:
| 参数 | 形状 | 说明 |
|---|---|---|
| 第 个编码器单元的隐状态 | ||
| 第 时刻解码器单元的隐状态 | ||
| 投影 到注意力空间 | ||
| 投影 到注意力空间 | ||
| 向量转标量(注意力打分) |
得到 后,我们可以使用 更新前一个decoder输出的隐状态 得到 :
其中, 仅作为 时刻的decoder单元的输入 , 时刻的输出仍为 。当我们仅使用 Seq2seq 架构提取序列特征时(即decoder单元直接输出隐状态),上述公式可直接使用。
面对不同任务时, 的计算不尽相同。一般来说,当decoder输出的序列是文本时,encoder、decoder单元接收的是词嵌入(表示词语的向量),输出的是各个词的概率值。这时,decoder的隐状态不直接输出,而是经过类FC层转换再输出,具体过程可由如下公式表示:
其中, 是输出的词概率密度向量中最大概率所对应的词(不是词嵌入),我们需要对这个词进行嵌入操作得到对应的词嵌入。不管 Seq2seq 的输入输出形式如何改变,我们都需要进行模型结构微调,使得encoder、decoder单元的I/O格式一致原因。
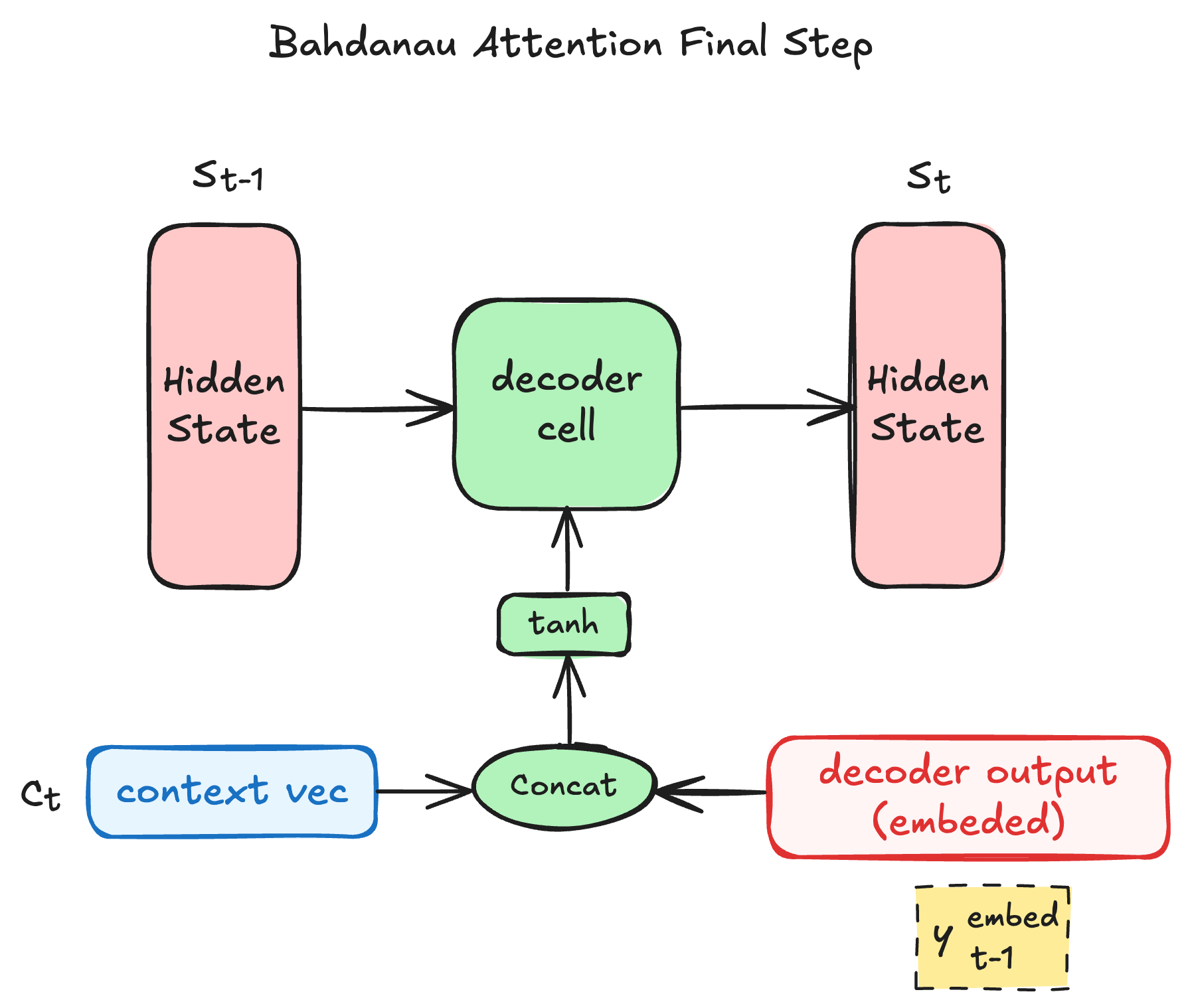
此外,Luong也提出了 Luong Attention 机制,这时一种乘性注意力机制。与之前机制不同,该机制在decoder输出时,采用的是当前时刻的隐状态 (这时 则作为decoder单元的输出);同时,其在计算注意力分数时,使用乘运算代替加运算。
| 名称 | 得分函数形式 |
|---|---|
| general常用 | |
| dot | |
| concat可选,加性 |
得到 后的注意力分数计算与上述机制相同,这里只介绍两种机制不同的地方,相关公式如下:
得到 后,我们可以使用 更新当前decoder输出的初始隐状态 得到 ,这时的 仅用作decoder的输出(间接参与输入)。然后我们可以再根据输出,计算得到下一个时刻decoder的输入 。同样,我们在构建 Luong Attention Seq2seq 结构时,也需要考虑encoder、decoder单元I/O格式的一致性。
根据论文中给出的公式()不难看出,CRM的attLSTM模块采用的是 Bahdanau Attention 机制。
👫 融合模块
根据CRM网络结构图可知,融合模块做的工作是将两个分支输出的时序特征进行一一拼接,最后再经由全连接层输出各类别概率。由论文可知,融合模块由FC+ReLU+FC构成,最后输出长度与类别个数相等的概率向量。需要注意的是,全连接层只接受一维向量,故CRM在将时序特征输入融合模块前,还进行了flatten处理。
4. 其他
下面选取介绍论文的余下内容。首先,论文的训练与评估细节参考如下表格:
| 内容 | 详情 |
|---|---|
| 训练设置 | 所有深度学习模型都使用Adam优化器和交叉熵损失函数进行训练,Adam配置参数与推荐值一致:、、,且学习率固定为。 |
| 评估指标 | ( Global / Local )、、() |
论文为了验证CRM方法的性能与模块的有效性,进行了 对比实验 、模块消融实验 。这与一般网络论文一致,但需要注意的是,论文还对CRM输入数据进行了对比实验,这说明CRM模型的光学分支只接受单一类型时序数据。实验结果如下图所示:
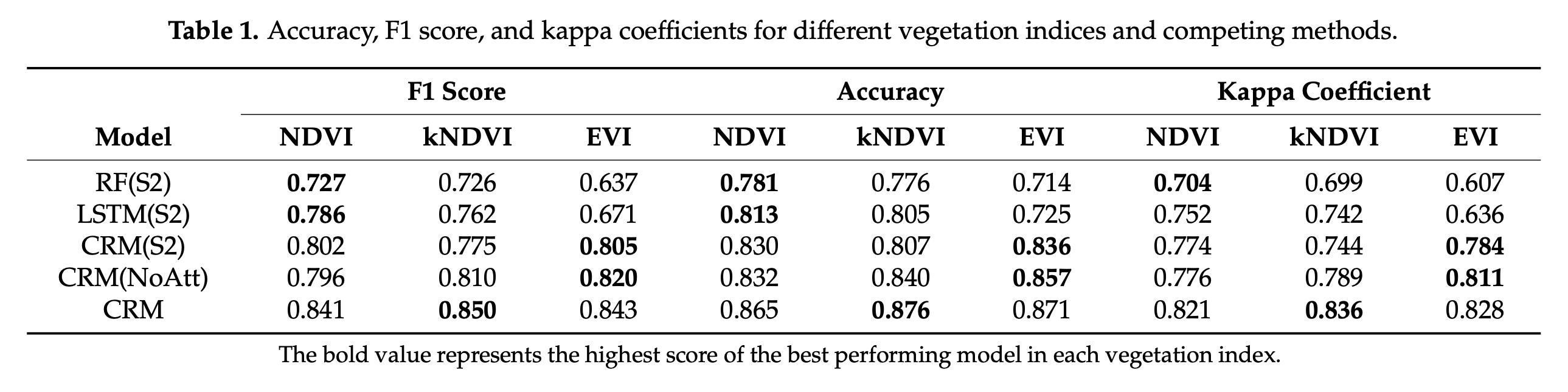
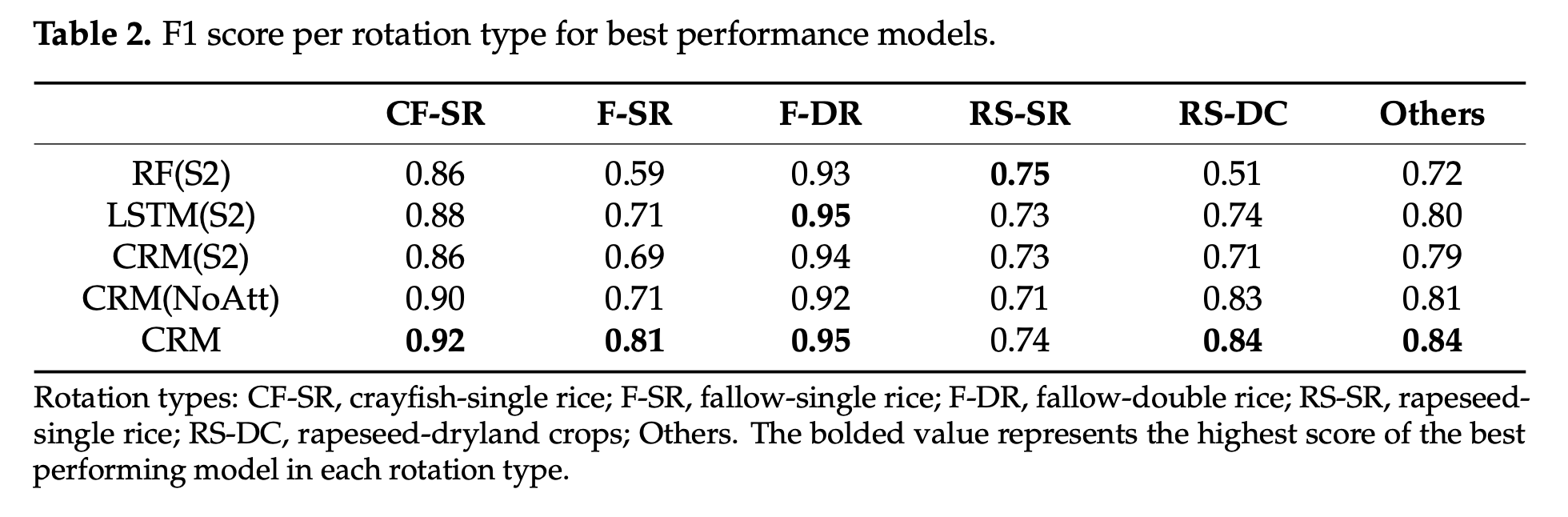
论文除了对各消融/对比项进行了 Global AC 的对比实验,还对其进行了各类别的 Local AC 的对比实验,结果如下图所示:
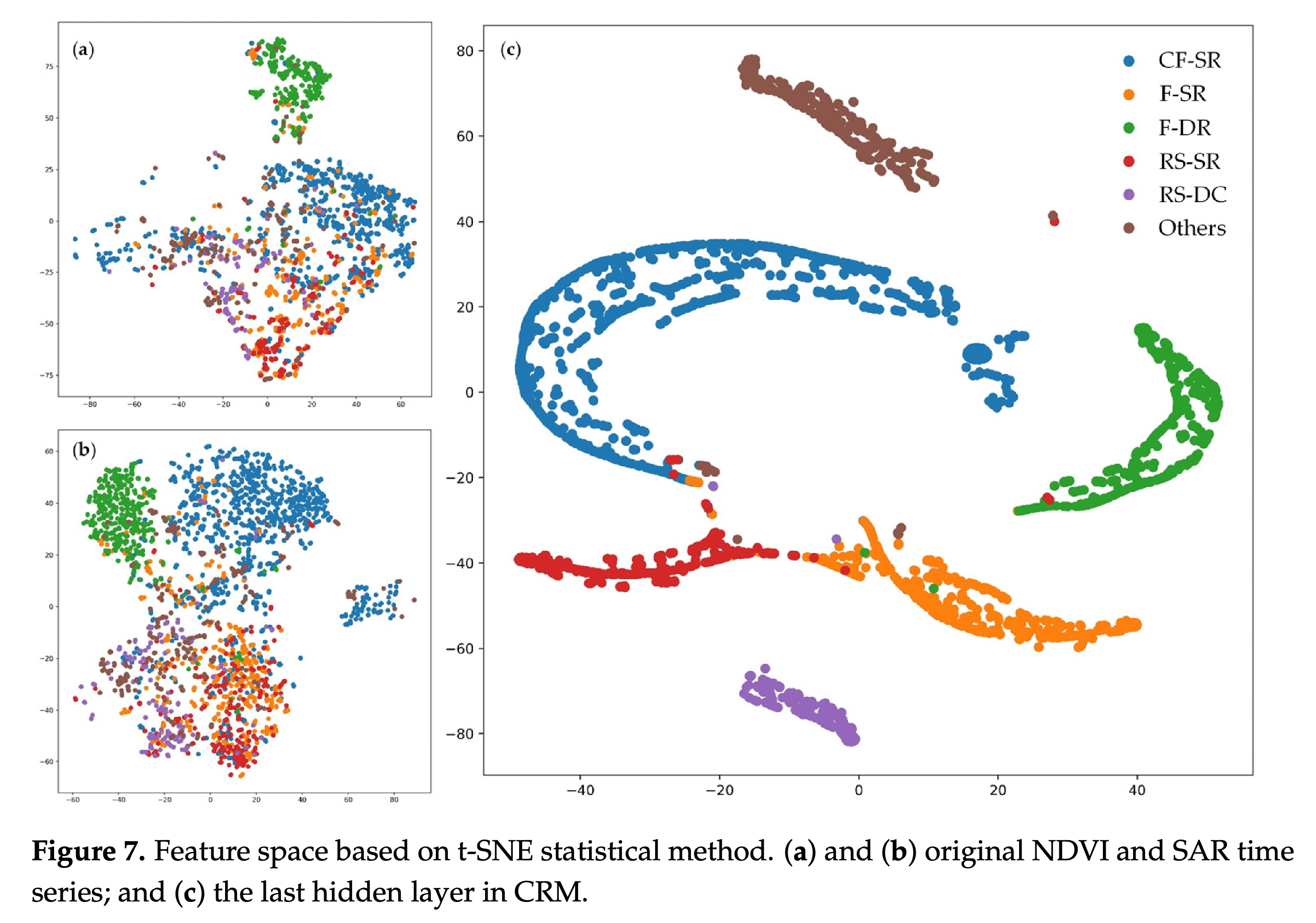
论文除了使用常见的方法进行模型性能评估,还使用了t-SNE方法可视化评估了模型分类性能,这步骤主要比较了原始数据(NDVI/SAR)和经过CRM提取后的特征(CRM最后一层隐藏层)在t-SNE方法下的特征空间下的个类别分布情况。这证明了CRM不需要对每一种单作作物的分布进行制图和关联,就能提取出隐藏在原始时序特征中的丰富的作物轮作信息。这段叙述原文如下:
It further demonstrated the feasibility of extracting abundant crop rotation information hidden in the original time series without mapping and linking individual monoculture crop distribution or utilizing absolute phenological thresholds to segment different crop types [8,10].
本研究进一步验证了,无需对各类单一作物进行制图与时序关联,也无需依赖绝对物候阈值来划分作物类型,即可从原始卫星时间序列中提取出丰富的作物轮作信息的可行性。
Transformer4SITS:基于像素的时序树种制图
1. 论文信息
| 属性 | 详细信息 |
|---|---|
| 标题 | 🔬 A spectral-temporal constrained deep learning method for tree species mapping of plantation forests using time series Sentinel-2 imagery 🔬 基于时间序列哨兵2号影像的人工林树种制图光谱时间约束深度学习方法 |
| 期刊 | 📚︎ ISPRS Journal of Photogrammetry and Remote Sensing 🌍 地球科学1区 [TOP] |
| 日期 | ⏲️ 2023-9-28 |
| 作者 | 👨🔬 ZeHua Huang |
| 关键词 | Tree species mapping、Key phenological stage、Transformer、Attention mechanism、Deep learning、Plantation forests |
本文提出了一种基于Transformer的像素级时序序列分类方法—— Transformer4SITS 。这里的“像素级”是指模型在分类时并不依赖目标像素邻域的空间特征,而是仅基于该像素在时间维度上的观测序列完成分类判别,这样模型只需实现时间编码即可完成分类。
在 章节中,作者回顾了已有相关研究:已有工作将Transformer引入基于高光谱影像的土地覆盖与作物制图任务。这些方法大多直接借鉴通用Transformer的设计思路,将某一像素点在单日获取的 高光谱数据 作为时序元素直接输入Transformer。
The Transformers utilize self-attention mechanism to model interaction between elements in the sequential data, and has been successfully applied to hyperspectral imagery-based land cover mapping, crop type mapping, etc. (Li et al., 2022; Tu et al., 2022; Zou et al., 2022).
However, the input time series contains numerous single-date images, and each single-date image provides massive spectral features (including spectral bands and various normalized difference indices). The abundant spectral features and dense observations greatly increased the size of the input data. Moreover, the sequential relation between single-date images (temporal sequence) in input vector was important for achieving typical temporal features; the correlations between spectral features should be also concerned to effectively combine the features to improve accuracy.
Moreover, increasing the model complexity of Transformer network to handle high-dimensional spectral-temporal features easily leads to overfitting problems.
Transformers模型通过自注意力机制建模序列数据中元素间的交互关系,已成功应用于基于高光谱影像的土地覆盖制图、作物类型制图等领域(Li et al., 2022; Tu et al., 2022; Zou et al., 2022)。
然而,输入的时间序列包含大量单日影像,每幅单日影像又提供海量光谱特征(包括光谱波段及各类归一化差值指数)。丰富的光谱特征与密集观测数据显著增加了输入数据量1。此外,输入向量中单日影像间的序列关系(时间序列)对提取典型时序特征至关重要2;同时需关注光谱特征间的关联性3,以有效整合特征提升识别精度。
此外,提高Transformer网络的模型复杂度以处理高维时空谱特征,很容易导致过拟合问题。
论文中提到的将通用Transformer用于高光谱像素级分类的相关问题非常有意思。结合 TF4SITS 的结构可以发现,这类方法使用的Transformer并没有进行 嵌入 |
embedding处理。这意味着模型的分类性能在很大程度上直接依赖于输入特征本身:
- 特征冗余风险1:输入特征缺少初步提取与压缩,不同特征之间可能存在高度相关性。若一些判别力较弱的特征在原始输入中占比较大,它们就可能掩盖真正关键的特征,从而削弱下游任务表现。
- 注意力权重分配受限3:由于缺乏 embedding ,Transformer的 实际上等于输入通道数。在自注意力机制中,特征的初始占比会影响注意力的聚合结果,使得判别性较弱但比例较大的特征被赋予过高权重,导致注意力机制难以充分发挥作用。
- 关于“序列关系”的疑问🤔2:理论上,Transformer对 单个 token 向量内部的维度顺序 是无感知的(注意力权重是:两个 token 的 维度内各特征一一对应计算,最后得出一个两者之间的相关性表示,与 维度内排序无关),这里为什么这样表述?
相比之下,Transformer4SITS 在此基础上进行了改进,其并没有采用常见的嵌入处理,而是采取了一种更直接的策略:将原始时序划分为若干子序列,分别输入Transformer进行建模,最后再通过融合模块整合。这种「拆分—聚合」的机制就是它的创新点。
需要注意的是,在处理 高光谱像素级分类 时,即便没有嵌入操作,输入 token 的维度通常也不会超过通用Transformer常用的配置(例如 )。因此,TF4SITS 的分块设计还可以理解为:
- 降低单个 token 的维度负担:减少模型复杂度,降低过拟合风险;
- 模拟多头注意力的思路:从不同子序列角度提取光谱判别信息,并在融合阶段加以整合,用于提升分类效果。
论文的研究流程图如下所示:
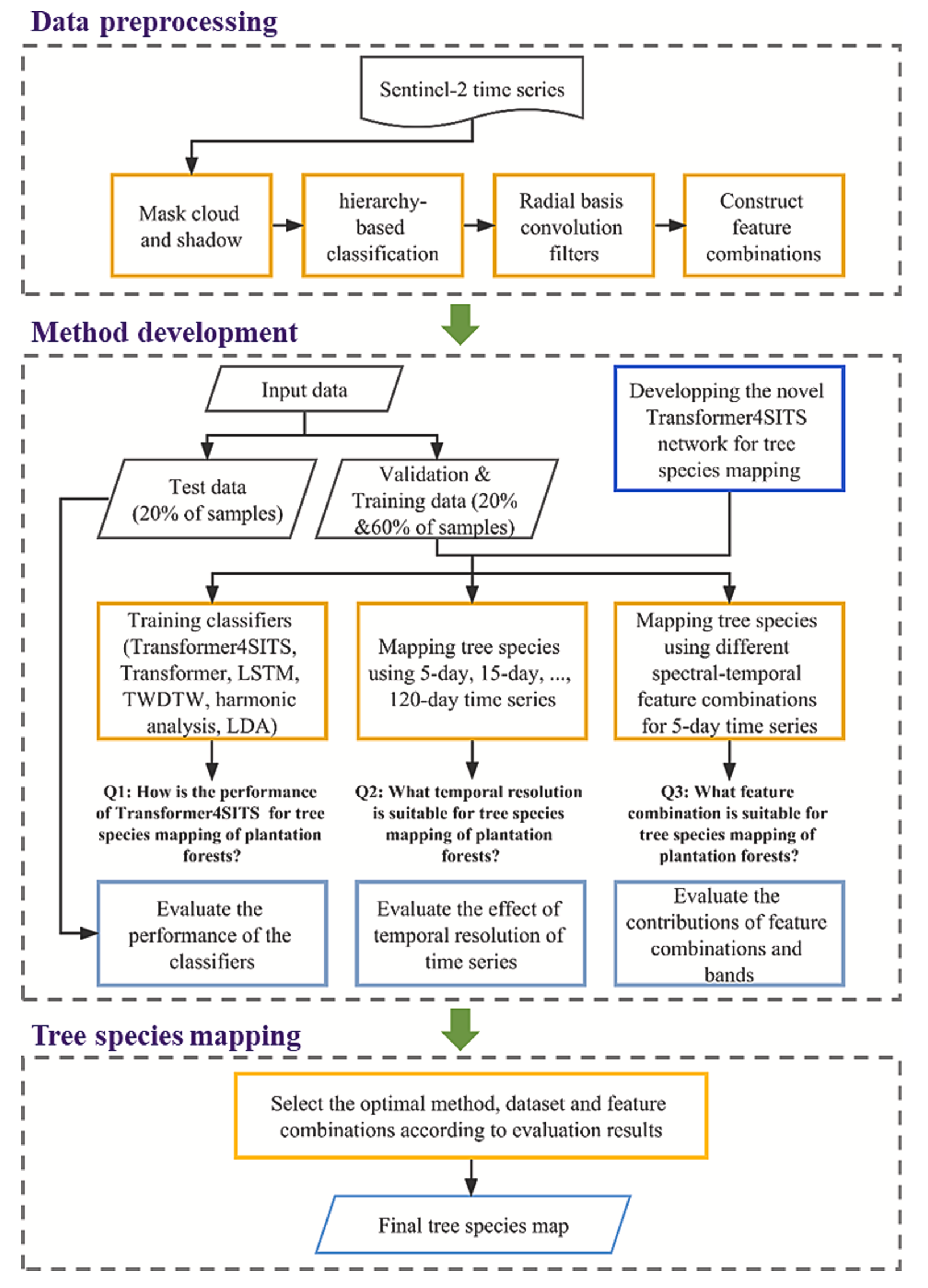
这篇论文是较为传统的遥感领域学术论文,这类研究通常会通过类似的流程图来概述整体框架,一般依次包含 数据预处理、方法开发(模型构建、对比与消融实验、实验结果分析)以及 制图 等环节。
2. 实验数据
论文使用实地采集的树种划分数据作为实验样本,由于 TF4SITS 处理的是像素基分类任务,这里的样本数量统计也是以像素为单位,具体统计数据如下:
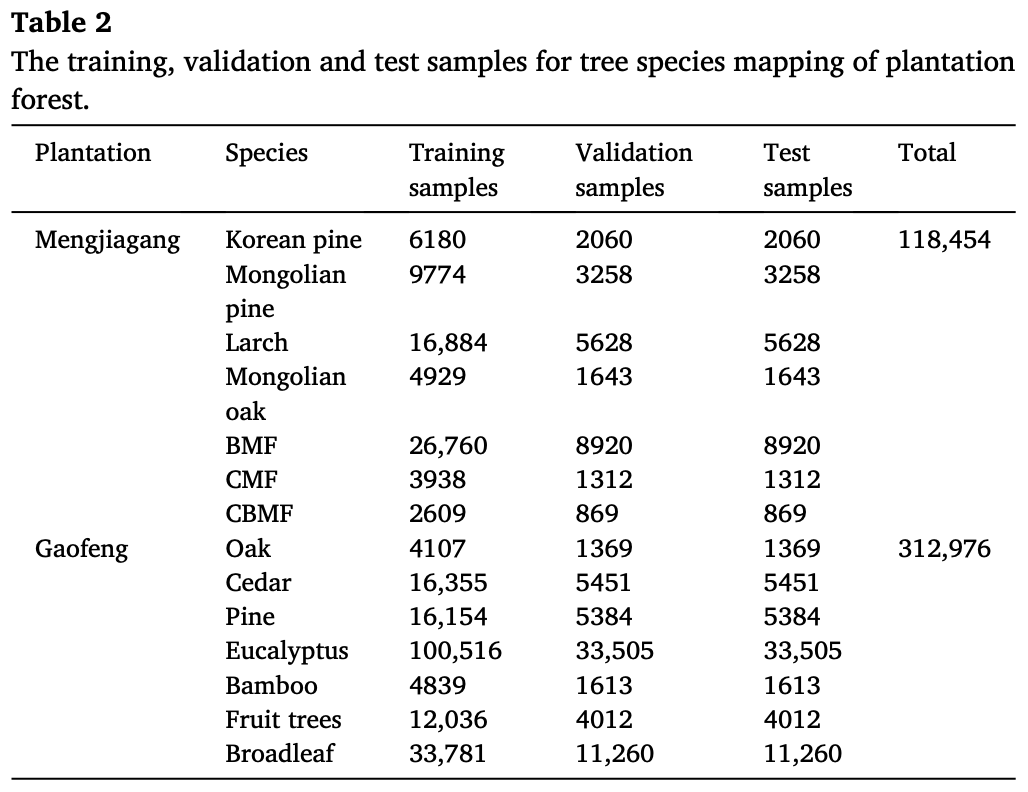
训练数据来自 Sentinel-2 影像。根据研究流程,数据预处理阶段主要包括 去云、层次分类 和 时序滤波。
去云与整合时序数据:使用 掩膜将云覆盖像素的各波段数据重置为 。这样得到的时序数据仍然较为稀疏,为提高数据稳健性,研究将连续年份的低云影像合成为新的 SITS 数据。原文描述如下:
However, the pixels with the value 0 or null resulted from cloud removal and random errors in processing also affect the data quality of the SITS. To overcome these problems, we combined all available Sentinel-2 images in continuous years (2018–2020 for Mengjiagang plantation, 2017–2020 for Gaofeng plantation) with cloud cover and cloud shadow less than to synthesize a new time series, which could increase the temporal resolution of observations and provide more clear images with little cloud.
然而,因云层清除及处理过程中的随机误差导致的0值或空值像素同样影响了SITS的数据质量。为解决这些问题,我们整合了连续年份内所有可用的 Sentinel-2 影像(孟家岗林场为2018-2020年,高丰林场为2017-2020年),筛选云量及云影覆盖率低于 的影像,合成新的时序序列。此举既能提升观测的时间分辨率,又能提供更清晰的低云影像。
PS:需要注意的是,此类通过合并不同年份影像以提升时间分辨率的做法,适用于树种识别等年际稳定性较强的地物类型,但并不适合如 湿地制图 等受年际变化显著影响的研究场景。
层次分类 |
hierarchy-based classification:在正式树种分类之前,研究将影像中属于Forest的像素提取出来。这样做的意义在于:- 有效避免了非森林区域中复杂背景特征导致的误判;
- 降低了分类器的学习难度,使其专注于树种类别的判别任务。
原文描述如下:
The forest areas were extracted for tree species mapping, which helps avoiding misclassification caused by confused features in non-forest areas and simplifies the classifiers to focus on tree species mapping.
森林区域被提取用于树种制图,这有助于避免因非森林区域混杂特征导致的分类错误,并简化分类器以专注于树种制图。
时序滤波处理:使用 加权组合的径向基卷积滤波器(RBF) 生成等时间间隔且无缺失的时间序列。具体实现如下:
Subsequently, a weighted ensemble of radial basis convolution filters (
RBF) was applied to produce a gap-free time series with a regular temporal spacing of 5 days (Hemmerling et al., 2021; Schwieder et al., 2016). The four utilized convolution filters had different kernel widths ( , , , and ), which were weighted combined to produce dense phenological profile and ensure the reliability of key phenological stages selection (Hemmerling et al., 2021). The weights of the 4 RBFs were both set to , which was determined by manual testing.随后,采用加权组合的径向基函数卷积滤波器(
RBF)生成间隔为5天的无间隙时间序列(Hemmerling et al., 2021; Schwieder et al., 2016)。所采用的四个卷积滤波器具有不同的核宽度 (、、 和 ),通过加权组合生成高密度物候剖面,确保关键物候阶段选择的可靠性(Hemmerling et al., 2021)。四种径向基函数的权重均设定为 ,该值通过人工测试确定。
在正式介绍 TF4SITS 模型结构之前,我们最后回顾一下其 输入特征 的构成。论文的实验部分主要关注三类实验:对比实验、SITS 时间间隔的消融实验 以及 不同特征组合的消融实验。其中,特征组合的设置如下:
| 组合序号 | 内容 |
|---|---|
| 组合一 | Sentinel2的10个波段+ 所有可能的归一化差异指数 (即 ,) |
| 组合二 | Sentinel2的8个波段+五种植被指数 |
| 组合三 | Sentinel2的8个波段+NDVI |
文中还提及了 原始光谱 与 植被指数 的适用领域,若想选择适用于自己研究的光谱特征,可以参考如下原文描述:
Original spectral bands such as the green band and the SWIR band are widely used to indicate greenness and foliar water content of vegetation (Ceccato et al., 2001; Pena et al., 2017). Spectral indices such as normalized difference vegetation index (NDVI), enhanced vegetation index (EVI), difference vegetation index (DVI), ratio vegetation index (RVI), soil-adjusted vegetation index (SAVI) etc. could describe leaf area index, leaf chlorophyll concentrations, ecological environment and green biomass of vegetation (Glenn et al., 2008; Hu et al., 2019; Huete et al., 2002; Ren et al., 2018; Xue and Su, 2017).
原始光谱波段(如绿波段和短波红外波段)被广泛用于指示植被的绿度和叶片含水量(Ceccato等,2001;Pena等,2017)。光谱指数如归一化差值植被指数(NDVI)、增强植被指数(EVI)、差值植被指数(DVI)、比值植被指数(RVI)、土壤校正植被指数(SAVI)等,可描述植被的叶面积指数、叶绿素浓度、生态环境及绿色生物量(Glenn et al., 2008; Hu et al., 2019; Huete et al., 2002; Ren et al., 2018; Xue and Su, 2017)。
3. 模型结构
论文提出的 TF4SITS 模型架构如下图所示:
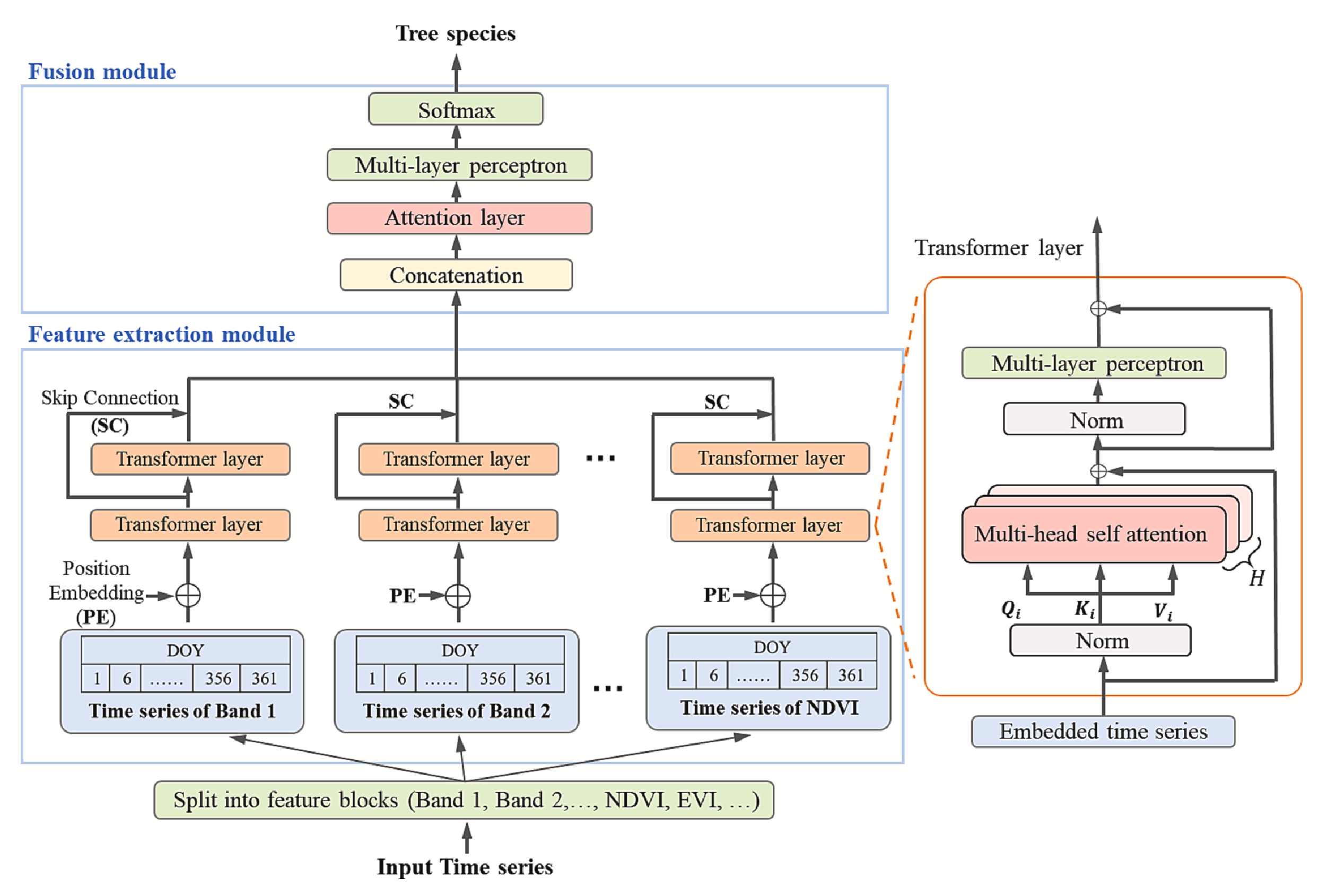
🐳 特征提取模块
在特征提取阶段,SITS 数据的输入形式为:
其中 表示光谱特征数, 表示时间序列长度。论文将不同光谱特征 逐一拆分,每个特征对应一个长度为 的时间序列:
经过位置编码与嵌入操作后,每个时序数据被扩展为 的向量,其中额外的 很可能是引入了 [CLS] token。由于Transformer不会改变输入维度,因此各分支的输出形状也保持为 。
根据论文描述可推断,每个分支的 。表面上看,这样的维度设计可能导致时间信息(DOY)嵌入后影响原始特征;但考虑到正弦-余弦位置编码公式本身依赖 ,在 的情境下,其影响只是对数值分布产生轻微偏移,不会造成原始信息的实质丢失。
🔥 融合模块
融合模块的原文描述如下:
In the fusion module, the output vectors of the feature extraction module are concatenated as a one-dimensional vector with the size of , and are input to the attention layer and a multi-layer perceptron to achieve the probability of tree species. As each species is represented by a specific value (such as 1 represents Larch, 2 represents Mongolian Pine, 3 represents Korean Pine, etc.), the classification results could be obtained from the output values.
在融合模块中,特征提取模块的输出向量被拼接为尺寸为 的一维向量,并输入至注意力层和多层感知器以获得树种概率。由于每种树种由特定数值表示(例如1代表落叶松、2代表蒙古松、3代表朝鲜松等),可通过输出数值获取分类结果。
对于这里的「注意力层」设计,论文并未给出充分细节,因而存在一定解读空间:
假设一:基于查询向量的聚合
如果输入视作 的矩阵,则可引入一个可训练的查询向量 来聚合光谱维度信息。考虑到光谱特征之间不存在顺序关系,我们可以在不引入位置编码的情况下使用此方法完成光谱间特征提取。
假设二:基于时间的自注意力
若作者将拼接结果视为一个长度为 的序列,则需要对其进行位置编码,每组 个特征共享相同的时间位置信息。在这种情况下,注意力层应当是自注意力机制,以保证能在全局范围内建模时间与光谱特征的交互关系。其输出维度仍为 ,可自然对接
MLP。
SITS-Former: 用于时间序列分类的预训练空谱时表征模型
1. 论文信息
| 属性 | 详细信息 |
|---|---|
| 标题 | 🔬 SITS-Former: A pre-trained spatio-spectral-temporal representation model for Sentinel-2 time series classification 🔬 SITS‑Former:一种用于哨兵2号时间序列分类的预训练空谱时表征模型 |
| 期刊 | 📚︎ International Journal Of Applied Earth Observation And Geoinformation 🌍 地球科学1区 [TOP] |
| 日期 | ⏲️ 2021-12-17 |
| 作者 | 👩🔬 Yuan Yuan |
| 关键词 | Pre-training、SITS、Self-supervised learning、Sentinel-2、Transformer |
本文将自监督学习应用到了遥感领域,提出了一种基于预训练Transformer的 SITS 数据分类方法—— SITS-Former 。该研究的创新点主要是:将自监督学习训练出的预训练模型迁移到遥感任务中。文中提到这是首次在基于patch的SITS表征学习中尝试自监督学习。整体方法分为两个阶段,如下图所示:
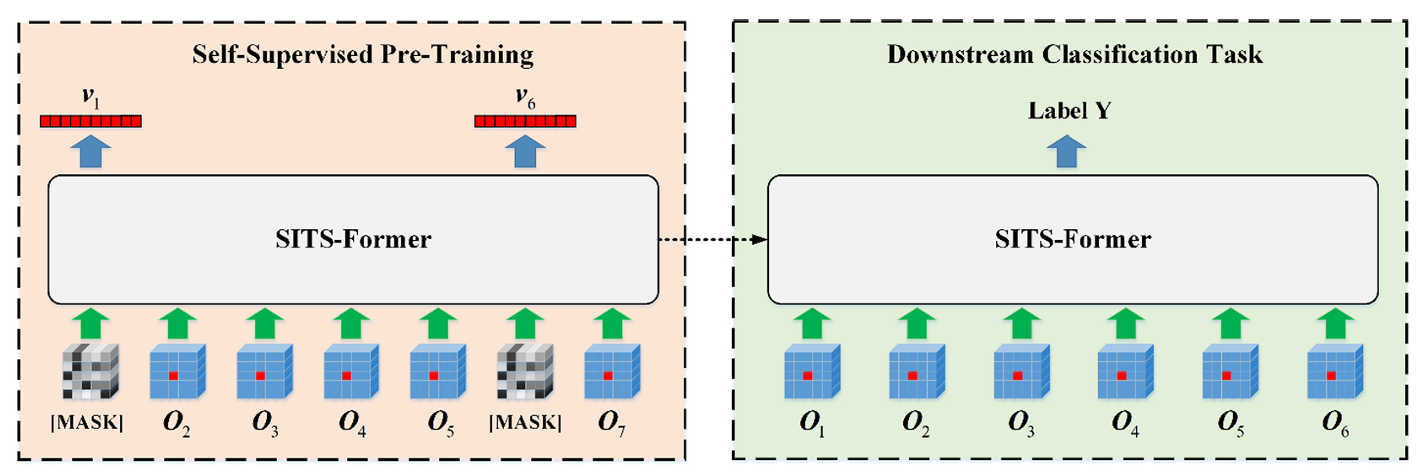
下面我们结合论文内容来具体看一下这两个阶段的细节。
2. 模型结构
SITS-Former 的模型结构如下图所示:
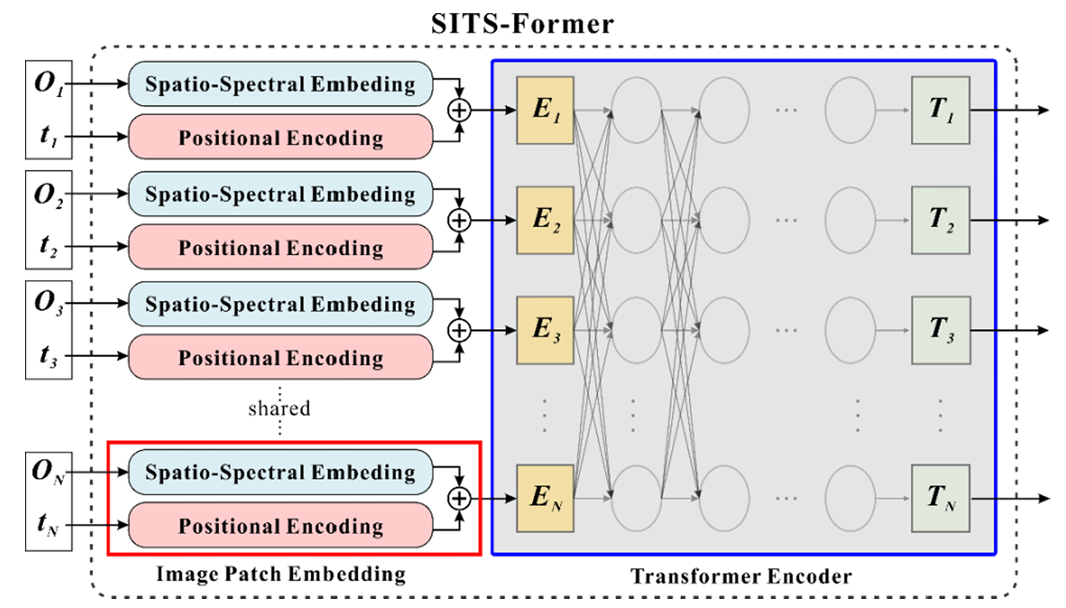
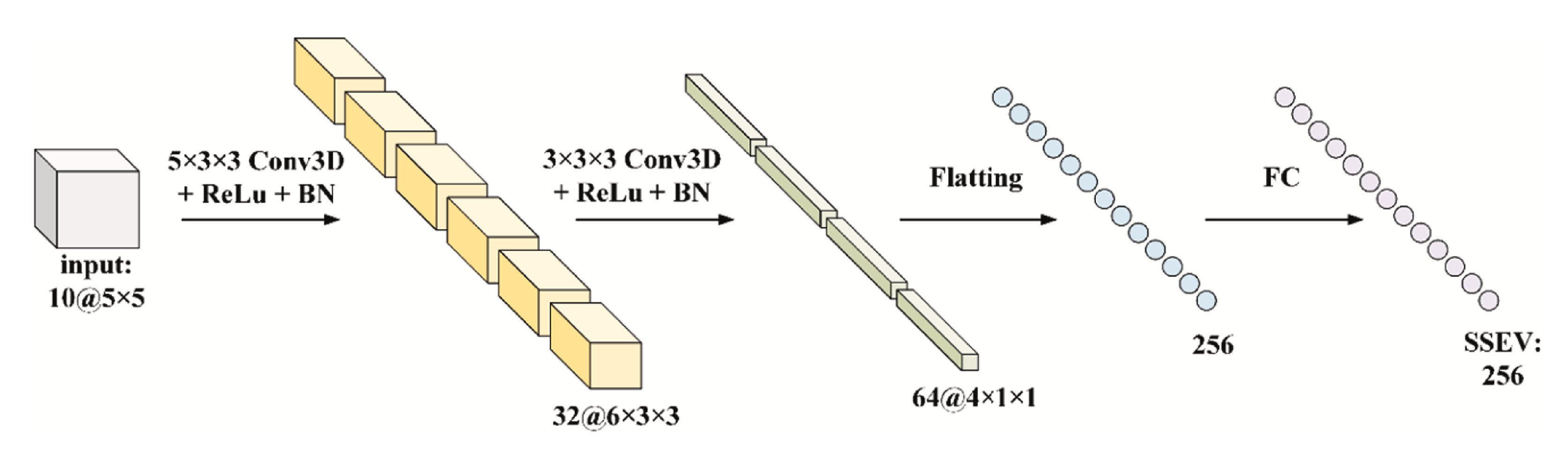
论文虽然花了大量篇幅介绍网络结构,但从本质上看,SITS-Former 由两个主要部分构成:前端的 空谱嵌入 模块和后端的Transformer编码器。Transformer机制比较常见,这里我重点解释一下空谱嵌入模块。
空谱嵌入模块接受一个形如 的patch作为输入,对应论文实验中channel=10、H,W=5,5。在经过一个kernel_size=(5,3,3)的Conv3D后,得到了尺寸为 的特征张量,下面我们了解一下三维卷积的原理。
🎲 三维卷积原理
卷积 | Convolution 最核心的思想是用一个 卷积核/滤波器 在输入数据上滑动,通过逐元素相乘再相加的方式,提取局部特征。二维卷积 主要用于处理图像,而 三维卷积 则用于处理在时间或体素维度上有连续性的三维数据。
在二维卷积中,如果输入是一幅多通道图像,一个卷积核在输出时会同时考虑所有通道的影响。但需要注意,卷积核并不会在通道维度上滑动,因此其输出始终是一张单通道特征图。为了获得多通道的输出,只需增加卷积核的数量,不同卷积核能够从不同角度提取空间特征,从而得到尺寸为 的特征图,其中 是卷积核的个数。
三维卷积的思路在此基础上进一步拓展,它在高度、宽度和深度三个方向上同时滑动卷积核,因此需要在这三个维度上分别设置 步长 | stride。与二维卷积不同的是,三维卷积的核深度并不要求与输入张量的深度维度严格对应,这使得它在处理体数据或时序数据时更加灵活。假设输入特征张量为 ,卷积核尺寸为 ,各维度步长为 ,那么这个卷积核的将会输出的特征张量 的尺寸为:
与二维卷积操作相同,我们同样可以通过设置多个三维卷积核,从不同角度提取特征,这样输出的最后一维数即为卷积核的个数 。
结合论文的空谱嵌入模块可以看到,SITS-Former 采用Conv3D对patch的空谱信息进行 token 化。由 figure 3.3 可知,该三维卷积模块三个维度的步长均设置为1(stride),而输出维度中的32对应卷积核的数量(kernel_num)。
😈 实现细节
我们将 空谱嵌入 后的时间序列送入Transformer中提取时序特征,这样我们便得到了patch中心像素的 时空谱 特征。但论文又是如何实现模型训练的呢?原文描述如下:
Formally, given an unlabeled pre-training set of samples. Let be the reflectance time series associated with the analyzed pixel of sample . We use a single FC layer to map the outputs of SITS-Former (i.e., ) into predictions, and use the L2 distance between the predictions and targets at all masked positions as the loss function:
where is a learnable weight matrix; is a binary vector cor responding to , with its element of 1 indicating a timestep being masked and 0 indicating non-masked; represents the element-wise product; represents norm.
形式上,给定一个包含 个样本的无标签预训练集 。设 为样本 中被分析像素对应的反射率时间序列。我们采用单层全连接层将SITS-Former的输出(即 )映射为预测值,并以所有遮罩位置上预测值与目标值的L2距离作为损失函数:
其中 为可学习权重矩阵; 是对应于 的二进制向量,其元素为 1 表示该时间步被遮蔽,0 表示未遮蔽; 表示元素级乘积; 表示 范数。
其中, 实际上是用于预训练的样本数量,在训练时通常按 batch 切分后输入模型训练。 是 token 化后的时序数据,与Transformer输出的 尺寸一致。而这里的全连接层可以理解为将预测结果映射回真实数据空间的解码器。
监督微调阶段的实现则相对直接:首先使用一个MaxPooling层对每个时间步输出 token 进行池化操作,如何再使用一个FC层实现 token 到分类标签的线性投影,从而实现对中心像素的分类任务。
论文中也提及了如何实现针对预训练模型的微调操作。我的理解是论文直接将 SITS-Former 的预训练参数直接作为初始值用于特定任务,至于如何更新 SITS-Former 参数,文中似乎只提及了预训练是的参数更新操作,并未说明预训练与监督微调任务的区别,详情请阅读原文。
3. 自监督学习
在传统的 监督学习 中,模型训练往往需要大量人工标注数据 。其数量需求通常与 任务类型、模型 以及 参数量 有关 。例如,当我们使用 ViT 训练一个通用任务(1000分类)的语义分割模型时,我们通常需要百万级规模的数据集,若想得到更好的效果,还可在更大的数据集(千万级)上进行预训练。虽然这种方式效果显著,但标注数据获取的成本往往极高。
相比之下,自监督学习 提供了一条新的路径。它不依赖人工标签,而是直接利用 原始数据本身 来构造「伪标签」,从而训练模型。通过解决这些预设的「预训练任务」,模型能够学到数据的通用特征表示。之后,再将这些表示迁移到具体的下游任务(分类、检测、分割等)时,即使标注数据有限,也能获得很好的效果。
由于这篇论文发表较早,文中提及的遥感领域自监督学习的基于 SITS 数据的相关研究只有论文作者之前的工作:
However, few studies try to exploit the notion of self-supervised learning for SITS analysis. We proposed the first pre-trained representation model called SITS-BERT (Bidirectional Encoder Representations from Transformers) for Sentinel-2 time series classification in a previous study (Yuan and Lin, 2021), which has shown encouraging performance. However, SITS-BERT was still pixel-based and did not take advantage of spatial information.
然而,鲜有研究尝试将自监督学习的概念应用于哨兵-2时序分析。我们在先前研究中(Yuan and Lin, 2021)首次提出名为SITS-BERT(基于Transformers的双向编码器表示)的预训练表示模型用于哨兵-2时序分类,该模型表现出令人鼓舞的性能。但SITS-BERT仍基于像素处理,未能充分利用空间信息。
论文中其余的关于自监督学习的相关综述这里就不过多讲解,详情请见原论文 章节。下面我们来看看 SITS-Former 的 自监督 代理任务是如何设置的。
从引言中不难发现,本文相较于前人相关工作的改进是:为待分类像素引入空间特征以调高分类表征。具体的是,SITS-Former 接受patch时间序列作为模型输入,通过提取空谱特征实现序列 token 化,然后将 token 序列输入到Transformer中用于下游任务。这里需要注意的是,输入的patch其实是作为中心像素的空间信息输入的,因此 空谱特征提取模块 提取出的信息对应的是中心像素。下面我们来通过原论文描述了解 SITS-Former 的代理任务设置:
Based on the principles of self-supervised learning, we develop a novel proxy task to pre-train SITS-Former without human annotation. Given a time series of image patches (centered at an analyzed pixel) with some patches being masked, the network is made to regress the central pixels of these masked patches based on the remaining ones. We hypothesize that the features learned in thus a way can capture subtle differences between various plant species.
基于自监督学习原理,我们开发了一种新型代理任务,可在无需人工标注的情况下对 SITS-Former 进行预训练。当给定一组以分析像素为中心的 图像块 序列(其中部分片段被遮罩)时,网络将根据剩余像素对这些遮罩片段的中心像素进行回归。我们假设通过这种方式学习到的特征能够捕捉不同植物物种间的细微差异。
对于这段描述有如下额外说明:
- 图像块序列:以待分类像素为中心的
patch为划分的时序卫星影像数据。当我们对这个数据进行 掩码 时,实际上是将某一些时间刻的影像用 噪声 代替,而不是掩盖patch中某些像素点的数据。 - 剩余像素回归:即没被掩码的时间刻的
patch数据。
需要注意的是,我们在将剩余像素输入Transformer回归时,实际上也将进行噪声掩码的数据也作为序列元素输入到模型当中。原文中对此掩码的描述为:对于每个时间序列,在输入网络前会随机用特殊填充矩阵[MASK]替换一定比例(论文实现中屏蔽率设置为 )的斑块。该填充矩阵与原始斑块维度相同,并在所有被遮蔽的时间步间 共享(即一个序列中所有被屏蔽时间步使用一个随机[MASK]矩阵代替)。[ MASK]的元素为来自正态分布的随机数。
而代理训练的训练目标则要求恢复所有被屏蔽时间步的分析像素,通过这种方式网络可以学习patch间的时空上下文关系以填补缺失内容。
借物表
| 参考资料 | 说明 |
|---|---|
| Bahdanau attention & Luong Attention - 十里清风 | CSDN文章|CRM参考 |


