论文信息
| 属性 | 详细信息 |
|---|---|
| 标题 | 🔬 Mapping hierarchical wetland characteristics by optical-SAR integration with collaborative spatial-spectral-temporal learning 🔬 通过光学合成孔径雷达与空间-光谱-时间协作学习的集成,绘制湿地分层特征图 |
| 期刊 | 📚︎ International Journal of Applied Earth Observation and Geoinformation 🌍 地球科学1区 [TOP] |
| 日期 | ⏲️ 2025-02-27 |
| 作者 | 👩🔬 Linwei Yue |
| 关键词 | Wetland mapping、optical and SAR、Multi-level classification、Deep learning |
要点
- 光学+SAR双分支多层次分类;
- 光学与SAR信息互补,使用双分支解决光学影像与SAR影像的异构特性;
引言
1. 写作大纲
不同于之前阅读的论文,这篇论文的引言重点主要放在:光学与SAR影像以及多分支网络上。并没有详细介绍研究背景,引言介绍的相关技术也是围绕这两点展开的,我总结的写作大纲如下:
- 背景引入:湿地制图对湿地保护的重要性;
- 技术发展现状:湿地制图研究中各影像特点 → 传统方法在复杂分类的局限性 → 多分支网络研究;
- 研究内容介绍:介绍HiWet-DBNet网络结构与研究贡献;
2. 具体内容
关于遥感湿地研究中,文中提及的需要SAR与光学结合的原因如下:
在湿地研究中,光学影像由于云污染的影响,使得我们无法对湿地频繁的动态变化进行持续监测。而SAR影像可以透过云层对地面进行监控,但雷达影像会受其固有的speckle噪声影响,且其雷达能量在水中穿透有限,无法检查水中沉水植被。
在本文研究中,光学与SAR的融合有助于解决:1)单用光学时的云污染导致的数据缺失;2)SAR无法检查水中的沉水植被;
为何要使用多分支网络处理SAR与光学影像的融合,文中也提及了原因:
传统SAR与光学影像的结合使用方法是:提取各自影像特征(例如:纹理特征,植被指数等)用于训练分离器;但光学与SAR影像的存储的信息是异构信息(信息表示的物理特性差距较大),在不知道哪些特征对分类有效时,单纯融合光学与SAR数据的固有特征(原始数据与部分先验特征)就很难取得很好的分类效果;
文中提及的先前的多分支研究有:
| 网络 | 年份 | 说明 |
|---|---|---|
| TWINNS | 2019 | 该网络由两个子模块组成,分别用于在Sentinel‑1和Sentinel‑2时间序列中发现空间和时间依赖性。 |
| WetNet | 2021 | 网络中不同分支获得的分类结果被集成以生成最终的湿地制图结果。 |
上述研究需要说明有:
- 空间依赖性:指同一时刻的遥感影像中,邻近像元(或区域)之间的关联性。
- 时间依赖性:指同一地理位置在不同时间点的影像数据中表现出的动态变化规律
研究区域与数据
对该论文的研究区域,我就不过多介绍,这里只贴一张研究区域及样本分布的论文图片作为参考:
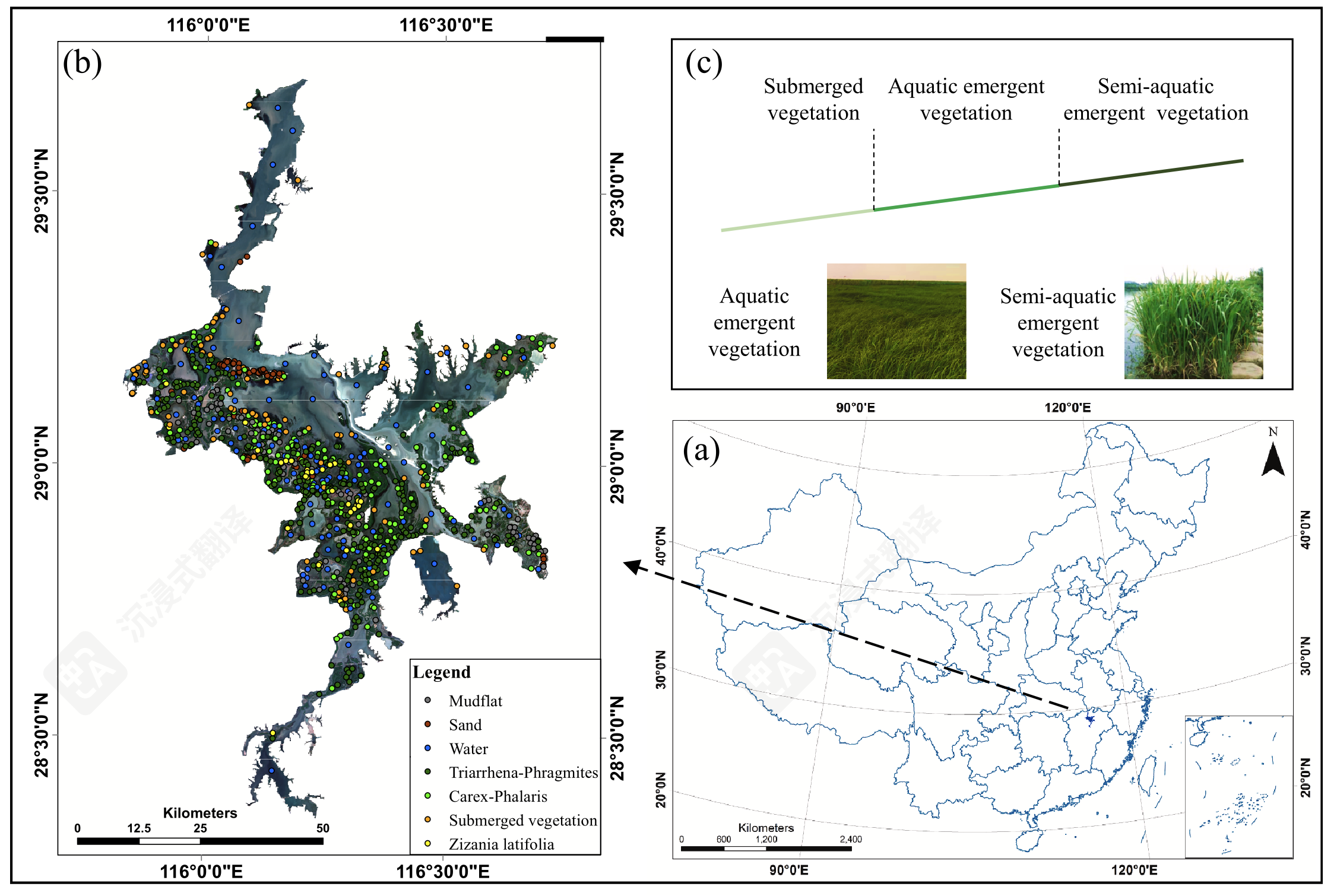
该研究选取时间同步的Sentinel-1/2影像(时间间隔在0到3天之间的Sentinel-1/2影像被认为时间同步),采用的卫星数据如下:
| 数据 | 数量 | 说明 |
|---|---|---|
| Sentinel‑1 Level-1 GRD | 10 | 10米分辨率双极化信息(VV和VH) |
| Sentinel‑2 L1C | 10 | 选取低于20%云/云影覆盖率的影像,进行几何校正、辐射定标,使用Sen2Cor掩膜去云(数据由哥白尼中心提供) |
研究使用的特征如下:
| 卫星平台 | 特征 | 描述说明 |
|---|---|---|
| Sentinel-1 | 垂直发射、垂直接收的 SAR 后向散射值 | |
| 垂直发射、水平接收的 SAR 后向散射值 | ||
| 极化比(VV 与 VH 的比值) | ||
| 极化差异指数: | ||
| Sentinel-2 | 可见光与近红外波段(10 米分辨率) | |
| 红边与近红外波段(由 20 米重采样为 10 米) | ||
| 短波红外波段 SWIR(由 20 米重采样为 10 米) | ||
| 归一化植被指数: | ||
| 归一化水体指数: |
方法论
1. 分类系统
该研究设计了一个三层分类系统,分类系统如下图所示:
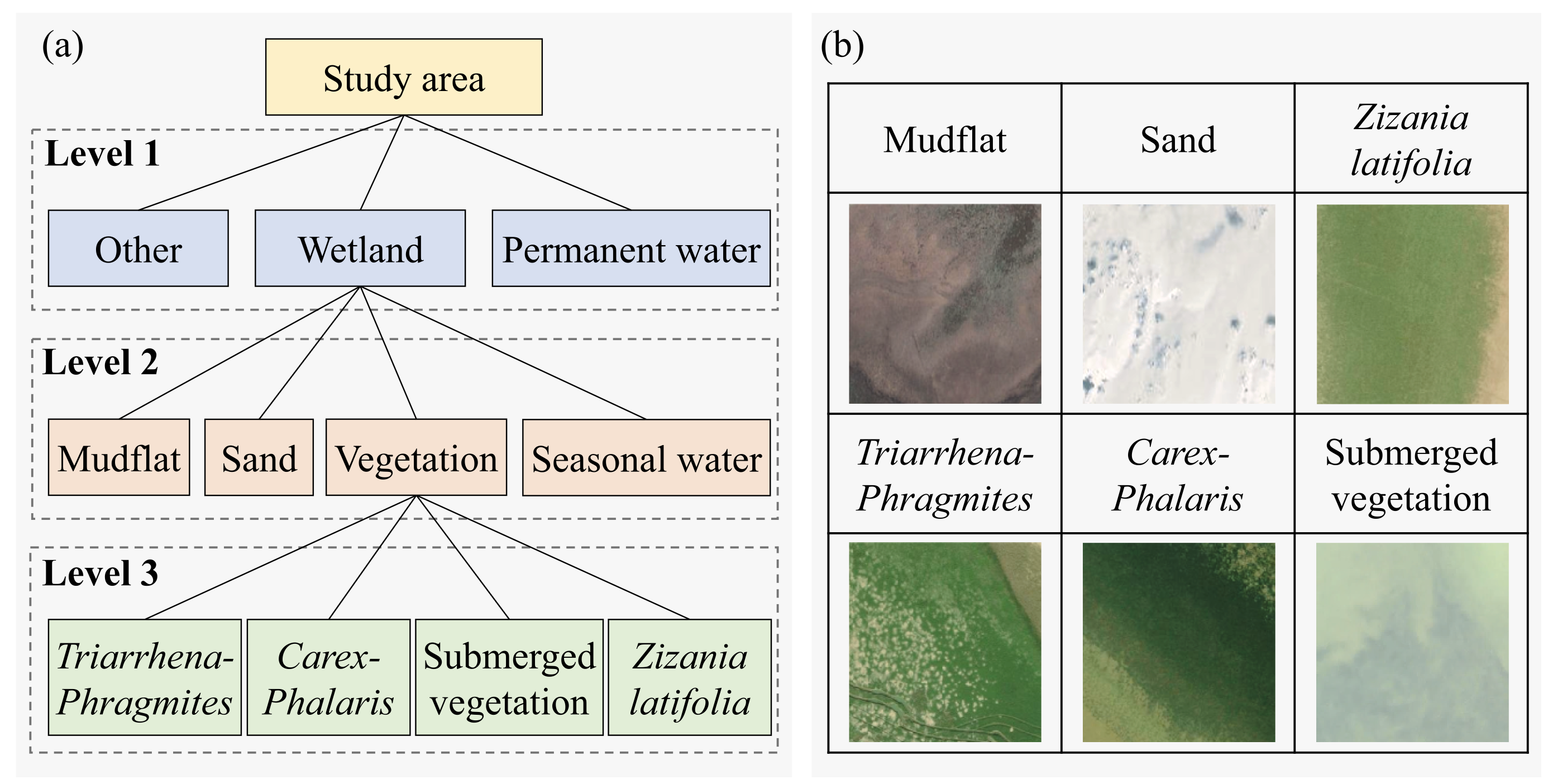
其中,第一层是在训练模型前分出,Other表示所有被淹没概率低于10%的所有陆地,Permanent water表示所有被淹没概率高于90%的水域,淹没概率采用Sentinel-2影像与 自动化水域提取指数 | AWEI 计算得出;
第二、三层的分类类别与常见鄱阳湖湿地地物类别相差不大,在这里我简单对比一下我们实地采样的湿地植被类别与论文中的类别,并梳理一下我们采样时的错误。该论文中湿地植被类型如下:
| 学名 | Triarrhena | Phragmites | Carex | Phalaris | Zizania latifolia | SV |
|---|---|---|---|---|---|---|
| 中文 | 南荻 | 芦苇 | 苔草 | 𬟁草 | 菰 | 沉水植被 |
参考图1,上述湿地植被类型可以被分为:
| 分组 | 说明 |
|---|---|
| 南荻-芦苇、菰 | 半水生挺水植被(semi-aquatic emergent vegetation) |
| 苔草-𬟁草 | 水生挺水植被(aquatic emergent vegetation) |
| 沉水植被 | 鄱阳湖有多种沉水植被,例如:酸模; |
除了上述植被,我们还实地采样了 苍耳 | Xanthium sibiricum 、 蓼子草 | Polygonum lapathifolia 的样方。需要注意的是:在采样过程中,我们将 南荻 误认为了 白茅,将部分 芦苇 误认为了 南荻。此外,沉水植被的标注也存在问题,我们将其标注为了 蔊菜 ;
此外,该论文还根据各类地物根据Sentinel-2统计的光谱曲线和SAR的NDPI特征分析了各类相似的地物,例如:T-P与Zizania的光谱相似性较高;Mudflat、Open water、SV的NDPI特征相似度较高,接着比较了各类为分开的类别在其他特征上的差异性。
这些分析信息为样本选择和结果验证提供了特征信息;
2. 网络结构
HiWet-DBNet网络的总体任务是接收大小为 的单幅光学特征和时序SAR特征,输出一个表示为分类概率向量,最终分类结果则选取 ,如下图所示;

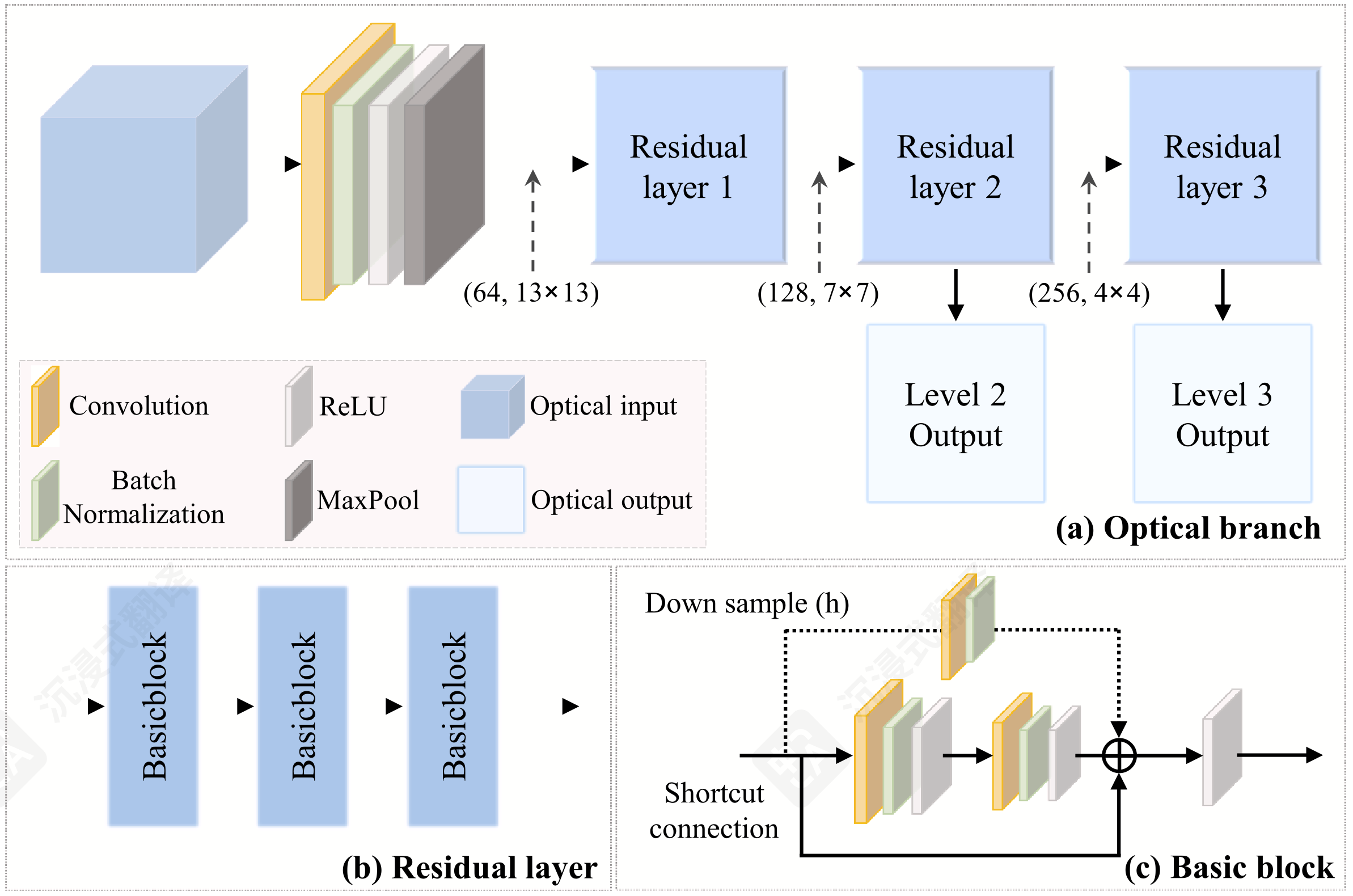
下面详细介绍一下网络的各个部分:
💡 光学分支
论文中提及该模块的作用为:该分支使用残差学习模块,从光学图像中捕获空间和光谱依赖性。该分支的具体内容为:
先对输入的单幅光学影像 [] 做典型CNN处理得到 []:
这里的12是表示输入影像光学特征的通道数,而64则是人为设置的隐藏层层数。经过此步骤处理,模型将原始光学特征转化为了初始特征图。其对应的源代码如下:
1
2
3
4
5
6
7# resnet.py/Resnet
self.conv1 = nn.Conv2d(12, self.inplanes,
kernel_size=3, stride=1,
padding=1, bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=1, padding=0)然后模型再对一个
batch中每幅初始特征图执行残差学习模块,残差块数学表示如下:作者在这里选择
BasicBlock作为残差块。以下是对应代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20# resnet.py/BasicBlock
# init
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(planes)
self.downsample = downsample
self.stride = stride
# forward
out=self.conv1(x)
out=self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)这里的
downsample实际上就是公式中的 用于调整输入张量的尺寸与输出残差尺寸一致,downsample适用的情况在这里就不过多介绍了。
在了解残差层之间的计算后,我们还需要了解模型是如何从中间特征图得到用于与SAR分支融合的特征向量的,计算代码如下:
1 | # resnet.py/Resnet |
虽然网络模型的图片中光学分支和SAR分支的中间特征图 融合 | fusion 的表现形式是二维张量。但在代码中两个分支融合时,都是flatten到一维张量后再cat在一起,详情请见 2.3. 特征融合 ;
🛰️ SAR分支
HiWet-DBNet的SAR分支由ConvLSTM+CNN构成,输入的时序SAR数据尺寸与光学分支一致。在这里简单介绍一下ConvLSTM与传统LSTM的区别。传统LSTM处理的是一维时序数据,传统LSTM单元如下图所示:
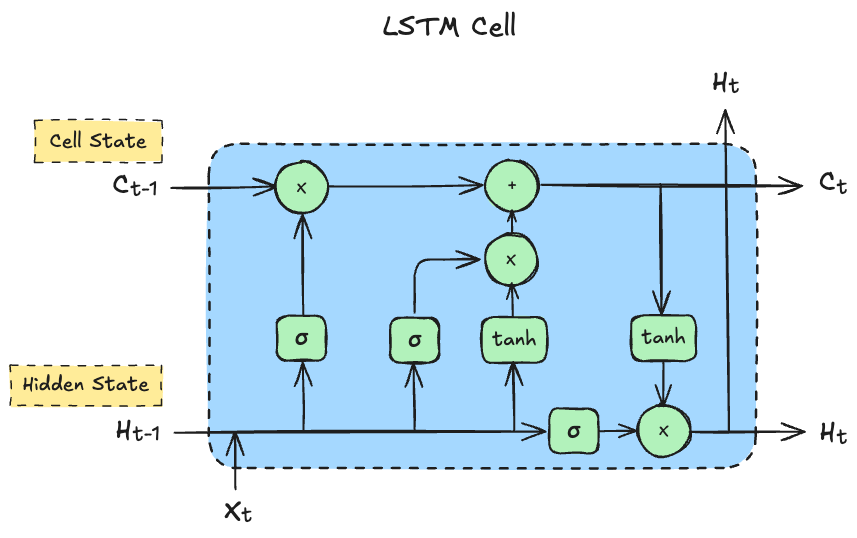
其中,为隐藏状态,记录短期信息;为细胞状态,记录长期信息。传统LSTM单元可用如下公式表示:
该公式将LSTM Cell中可以并行计算的部分用矩阵运算表示,并将隐藏层与时刻输入的运算用cat组合在了一起:例如遗忘门由 改写成了 ,当然 也是由 和 拼接而成。由上述公式可见,传统LSTM中使用到的都是全连接操作( 与 都是一维向量)。
传统LSTM不能很好的处理时序图像数据,我们可以使用卷积代替全连接,并稍微更改传统LSTM的网络结构,得到ConvLSTM:
其中 表示卷积操作, 表示逐元素乘法(Hadamard product);ConvLSTM同传统LSTM一样,ConvLSTM Cell间输入输出张量的维度与尺寸保持着一致性,以便与多个Cell的串行运行。以下是ConvLSTM Cell中各个部分的维度:
| 名称 | 尺寸格式 | 说明 |
|---|---|---|
X_t |
(C_in, H, W) |
当前输入帧 |
H_{t-1} |
(C_hidden, H, W) |
上一隐藏状态 |
C_{t-1} |
(C_hidden, H, W) |
上一记忆单元 |
i_t, f_t, o_t |
(C_hidden, H, W) |
门控向量 |
C̃_t |
(C_hidden, H, W) |
候选状态 |
C_t |
(C_hidden, H, W) |
当前记忆单元 |
H_t |
(C_hidden, H, W) |
当前隐藏状态(输出) |
(只有针对的卷积操作,通过更改卷积核的数量,改变了输入输出的维度)
HiWet-DBNet的SAR分支如下图所示:

这里需要注意在模型总体网络结构图中,SAR分支的两个数据似乎是两个ConvLSTM串行学习,但实际上是拆分了多层ConvLSTM的输出,再对两个输出进行卷积处理。最后同光学分支一样,将二维特征图拉伸为一维再做全连接映射。SAR分支核心代码如下:
1 | # sar_branch.py/SARBranch |
模型结构如forward所示,在这里不做过多讨论。模型实现代码中ConvLSTM直接使用了第三方实现的模块,代码中需要注意的地方有:
- ConvLSTM输出:
rnn_output[0][:, -1, :, :, :]中,[0]表示第一层ConvLSTM的输出,,-1,表示该层中最后一个ConvLSTM Cell的输出。不难发现,ConvLSTM中Cell的个数与时序的长度一致,测试数据中为15; - 测试数据:代码中使用
from torch.autograd import Variable生成测试数据,确保模型结构的正常运行。其中,64应该是一个batch的大小,而4则对应C_in,即SAR数据的特征数。
🤝 特征融合
经过上述计算,我们从两个分支中各得到了两个一维特征向量(不考虑batch):output_level2_connect (6727)、output_level3_connect (4096)。HiWet-DBNet的融合处理特别简单,先将对应的特征向量cat到一起,得到一个两倍长度的特征向量,再用全连接网络+softmax得到每个层次分类的概率向量,用于分类训练。以下是论文中相关公式:
需要注意的是,公式中已经在SAR分支代码中执行,因此上述公式仅需实现concat+全连接即可。此外,这里光学分支与SAR分支的序号不一致(例如 与 )是因为,我们使用的是光学分支的 2,3两层ResLayer输出 和SAR分支的 1,2两层ConvLSTM层输出。
其实现代码如下:
1 | def forward(self, optical_data, sar_data): |
最后HiWet-DBNet使用 焦点损失 | Focal loss 函数来解决 类别不平衡问题 (类别不平衡时,直接使用常规损失函数,模型会偏向学习多数类,忽略少数类):
整个模型的损失函数是一个 多任务目标函数 | multi-task objective function ,包含两部分:
- 雷达图像输出的分类损失(使用浅层和深层特征);
- 联合分类损失:结合浅层与深层特征(从雷达和光学图像)所获得的联合分类结果的损失。
这样设置损失函数,模型可以在光学图像不可靠时依然能够准确分类。公式如下:
其中参数设置为:、、、;实现代码如下:
1 | # Train_.py |
实验
1. 实验数据
论文使用的实验数据如下表所示:
| Land-cover type | Training samples (pixels) | Validation samples (pixels) | Test samples (pixels) 2021/03/22 |
Test samples (pixels) 2021/05/01 |
|---|---|---|---|---|
| Water | 2492 | 623 | 936 | 947 |
| Mudflat | 2988 | 747 | 964 | 1248 |
| Sand | 1352 | 338 | 736 | 744 |
| Triarrhena–Phragmites | 3604 | 901 | 650 | 856 |
| Zizania | 876 | 219 | 354 | 315 |
| Carex–Phalaris | 3040 | 760 | 550 | 1033 |
| Submerged | 1248 | 312 | 300 | 407 |
| Total | 15,600 | 3900 | 4490 | 5550 |
上述数据显然不是的倍数,说明本文是以分类像素(patch)作为样本计数。在论文 3.4. 实施与验证 章节中,作者介绍了这些实验数据的由来:
在收集训练和测试样本的过程中,使用了谷歌地球上的高分辨率图像和覆盖研究区域的多源土地覆盖产品作为参考。总体而言,选择了 13 张在不同日期获取的高质量图像来生成样本。考虑到鄱阳湖湿地的季节性动态,我们选择了两个在干季( 2021 年 3 月 22 日)和干湿季节过渡期( 2021 年 5 月 1 日)获取的图像,这些图像植被覆盖丰富,用于评估分类结果。
这说明训练/验证集来自全年不同时间段标注的数据,而测试集选取了植被区分度明显的影像。需要注意的,这里提及的 13幅 影像与文章开头提及的 10幅 影像数目上不匹配,这尚不清楚原因(也许是我理解错误)。
2. 基准模型
由于本文分类系统的特殊性,文章除了对基准模型在全体分类类别上进行了模型评估,还单独对VBI算法在沉水植被上进行了结果分析(略)。相关基准算法有:
- RF
- VGG-13 [2015]
- 分支卷积网络 |
BCNN[2017] - WetNet [2021]
- WetMapFormer [2023]
具体精度评估表格请查看论文原文,这里只贴出 2021/3/22 测试数据的层次分类精度分析表格:
| Model | OA (%) | Veg. UA | Veg. PA | Mudflat UA | Mudflat PA | Sand UA | Sand PA | Water UA | Water PA |
|---|---|---|---|---|---|---|---|---|---|
| HiWet-DBNet | 91.59 | 94.02 | 92.37 | 83.32 | 96.37 | 97.44 | 82.61 | 93.20 | 92.31 |
| RF | 80.68 | 85.25 | 81.77 | 61.16 | 73.03 | 97.30 | 78.26 | 85.98 | 88.46 |
| VGG | 88.22 | 95.00 | 87.65 | 73.93 | 93.57 | 94.85 | 75.00 | 91.77 | 94.12 |
| BCNN | 87.07 | 91.90 | 92.07 | 77.60 | 95.23 | 89.65 | 58.83 | 89.35 | 92.31 |
| WetNet | 89.70 | 89.80 | 90.60 | 84.30 | 93.40 | 94.40 | 80.20 | 92.80 | 92.10 |
| WMF | 90.61 | 93.83 | 90.65 | 86.88 | 92.01 | 92.50 | 80.43 | 88.42 | 97.12 |
| Model | OA (%) | T–P UA | T–P PA | C–P UA | C–P PA | SV UA | SV PA | Zizania UA | Zizania PA |
|---|---|---|---|---|---|---|---|---|---|
| HiWet-DBNet | 88.51 | 94.91 | 86.00 | 76.52 | 91.82 | 88.85 | 79.67 | 88.24 | 76.27 |
| RF | 78.11 | 95.65 | 78.26 | 62.67 | 90.36 | 85.71 | 60.00 | 85.71 | 61.02 |
| VGG | 83.76 | 93.05 | 76.15 | 71.53 | 90.00 | 91.49 | 71.67 | 82.16 | 62.43 |
| BCNN | 82.18 | 97.43 | 81.54 | 64.38 | 93.64 | 90.83 | 69.33 | 78.17 | 62.71 |
| WetNet | 84.20 | 91.70 | 83.70 | 76.50 | 82.90 | 65.30 | 69.00 | 61.60 | 63.00 |
| WMF | 84.70 | 93.19 | 73.69 | 64.29 | 93.64 | 92.34 | 68.33 | 81.82 | 61.02 |
3. 消融实验
本文还对两个分支进行了消融实验,并对总体精度和单个类别精度进行了分析。这里只列出总体精度,其他信息请参看论文原文,表格如下:
| Date | Level | HiWet-DBNet | DBNet-optical | DBNet-radar |
|---|---|---|---|---|
| 2021/03/22 | Level 2 | 91.59 | 86.36 | 75.67 |
| Level 3 | 88.51 | 80.67 | 71.49 | |
| 2021/05/01 | Level 2 | 92.05 | 88.66 | 78.42 |
| Level 3 | 88.61 | 82.38 | 72.36 |
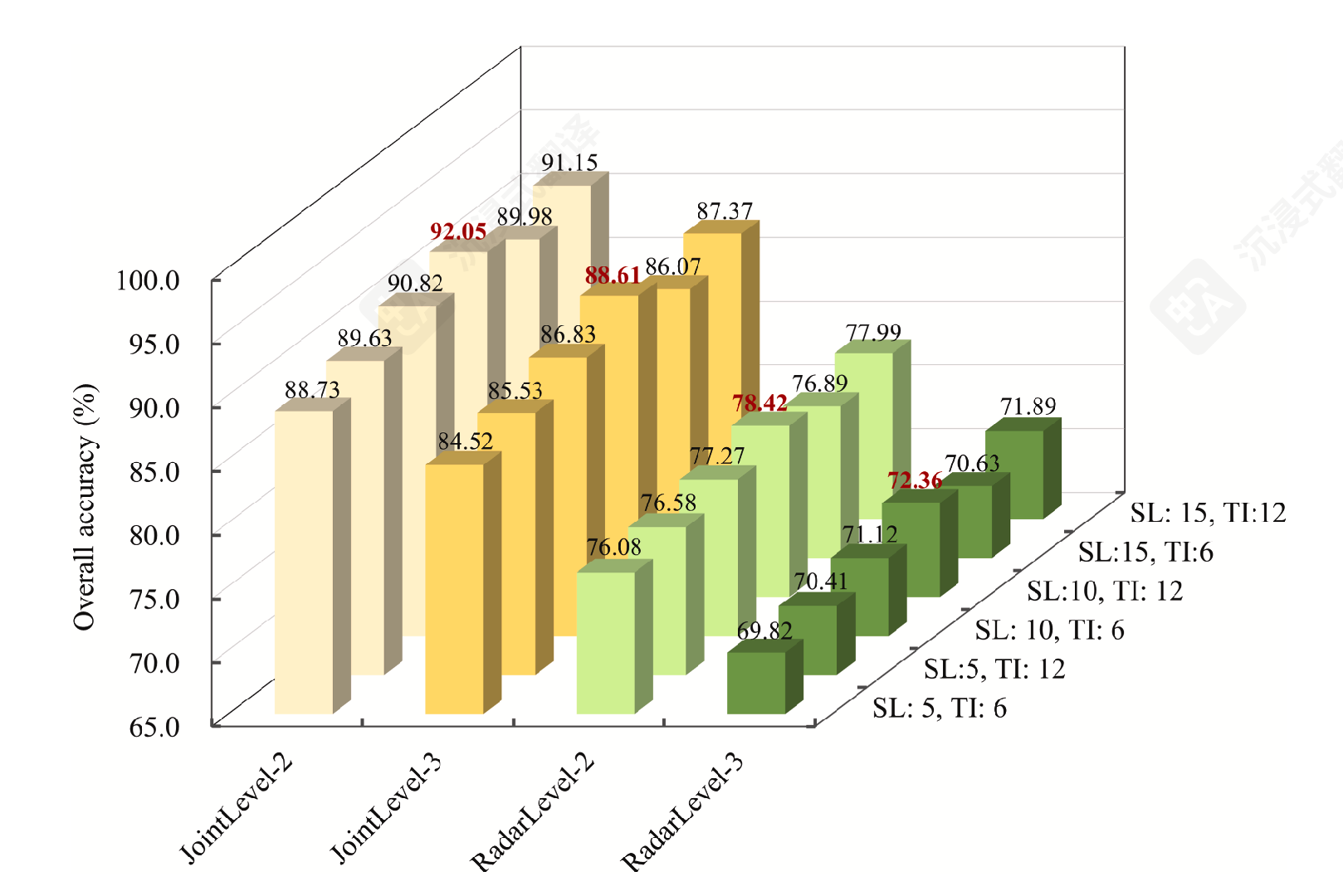
4. 时间窗口
HiWet-DBNet的SAR分支部分接收的是时序数据输入,因此本文还对输入的时间序列参数设置进行了分析。影响时间窗口的超参数有:时间间隔(TI)、序列长度(SL)。
论文前面部分没有详细提及时序窗口是如何设置的,这里才介绍了相关参数设置。由SL参数常设置为奇数猜测,时间窗口是以样本时间为基点,输入左右各选择 个时间间隔为 的SAR时序合成数据,作为模型SAR分支输入。
为了不对SAR数据进行时序合成,论文将TI值设置为 6/12(是Sentinel-2时间分辨率的整数倍)。将SL设置为 5/10/15,进行时间窗口参数组合实验,实验结果如下:
总结
在阅读完这篇论文后,我还是对其实验数据存在一些疑问,待后续阅读时补充和修订。相关疑问如下:
- 对于SAR数据,我的理解是选择离光学样本的时间点最近的SAR影像,将其作为SL中心并获取时间窗口内的SAR影像。但论文中并未有确切描述文本。
- 对于光学数据,论文中描述的实验样本的个数存在上下文不一致。
此外,本论文Github仓库为 HiWet-DBNet。


